SpectroDive 方法开发流
从 library / FASTA / sequence list 到 panel、RT calibration、method export 和 targeted analysis 的关系图。
SpectroDive Prepare
Targeted method development 覆盖
panel generation、panel import、panel splitting、
modified panel、RT calibration、method export 和
SureQuant。核心在于把 panel 结构、RT 校准和方法导出连成一条完整的方法开发链。
Orientation
相比 discovery 软件,SpectroDive 的核心挑战不在“找到尽可能多的蛋白”,而在“如何把有限目标物设计成稳定、可调度、可解释的 targeted assay”。Prepare Perspective 正是承载这个任务的地方。
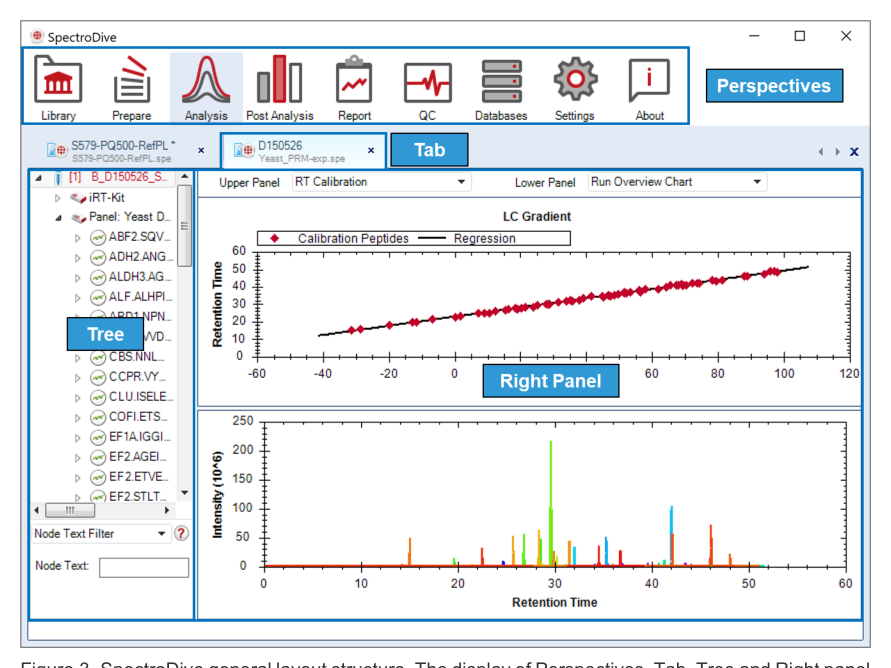
从 library / FASTA / sequence list 到 panel、RT calibration、method export 和 targeted analysis 的关系图。
Panel Sources
SpectroDive 支持三类 panel 来源:spectral library、FASTA 和 sequence list。三类来源对应不同的知识基础和质量边界,不能混作同一种输入。
这是最稳健、也最接近真实观测谱图的 panel 来源,适用于 biomarker 验证、候选迁移和有历史项目积累的实验室。panel 不是一份清单,而是 library 中 assay 信息的 targeted 选择。
这条路线适用于没有现成 library、但目标蛋白明确的场景。它把 digestion rules、charge states、修饰和 fragment selection 提前编码进 panel 设计过程。in-silico 不等于任意生成,它仍然依赖明确规则。
这一路径适用于已有目标肽序列、想快速构建 assay panel 的情况。sequence list 更像人工定义入口,后续依然要补齐 charge、fragment、label 和 iRT 等关键信息。
| panel 来源 | 适合什么情况 | 最容易踩的坑 |
|---|---|---|
Spectral Library |
已有 discovery 结果、已有历史库、已有 commercial panel 文件 | 把 library 里的 assay 当成最终 panel,不再做 targeted 层面的筛选和 split |
FASTA / in-silico |
目标蛋白明确但没有现成实验库,希望快速建立理论 panel | 低估 digestion rules、修饰、charge 和 fragment 过滤对 panel 质量的影响 |
Sequence List |
已确定目标肽段,想快速搭一个初版 assay panel | 只给序列,不补齐 iRT、fragment、label 和 response factor 等后续关键字段 |
Panel Schema
panel 字段是 SpectroDive 最值得反复训练的内容之一。因为一旦这里定义含糊,后面的调度、峰提取、绝对定量和 refinement 都会失去基础。
| 字段 | 在软件里的作用 | 关键解释点 |
|---|---|---|
Q1 / Q3 | 定义 precursor 与 transition / fragment 的理论 m/z | 绝不能随意四舍五入,它直接决定 transition 是否能被正确调度和识别 |
iRT | 把保留时间投影到标准化坐标系 | 如果 iRT 错,scheduled window 和峰提取都会出问题 |
RelativeFragmentIntensity | 帮助 transition ranking 与信号优先级判断 | 不是装饰列,它会影响检测限和 fragment 选择 |
ModifiedSequence / ProteinId | 连接位点、肽段和蛋白归属 | 如果想做修饰位点或标记通道,这两列必须提前规划 |
CompensationVoltage / IonMobility | 连接 FAIMS、TIMS 或其他离子淌度相关采集条件 | 这是高级 targeted workflow 的正式字段,不该等到后面分析时才想起 |
PeptideResponseFactor / ProteinScalingFactor | 服务绝对定量和浓度换算 | 如果只在分析后才想起这些字段,通常已经太晚 |
Q1 / Q3 / iRT / Sequence / Charge / Fragment 这些列决定 transition 身份和调度边界。它们缺失时,不是信息少一点,而是方法逻辑本身不完整。
ResponseFactor、ScalingFactor、CompensationVoltage、IonMobility、label 相关列会直接决定这个 panel 是不是只能做“能跑”的基础版,还是可以进入绝对定量和高阶调度。
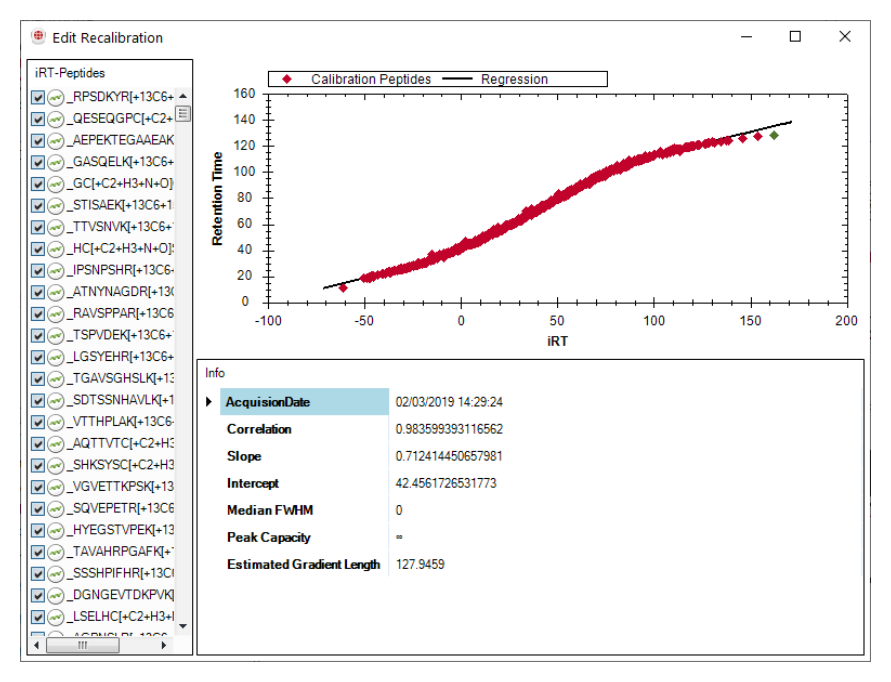
Q1 和 Q3 必须保持理论 m/z 精度,不能四舍五入,因为这会直接影响 transition 的准确性。iRT 是最关键的调度列之一。若没有经验 iRT,软件可以预测;但 empirically determined iRT 会显著提升速度与结果质量。RelativeFragmentIntensity 不是装饰性信息,它能改善 detection limit;StrippedSequence、PrecursorCharge、FragmentType、FragmentNumber、FragmentCharge 和 ModifiedSequence 共同定义 transition 身份与打分语义。PeptideResponseFactor、ProteinScalingFactor 及其单位列。这些列定义了如何把 target/reference ratio 变成 peptide 或 protein absolute quantity。RT Calibration & Export
Prepare Perspective 的真正难点不在于导出一个方法文件,而在于先建立 RT calibration、split panel 和 calibration run 对 method export 质量的约束关系。
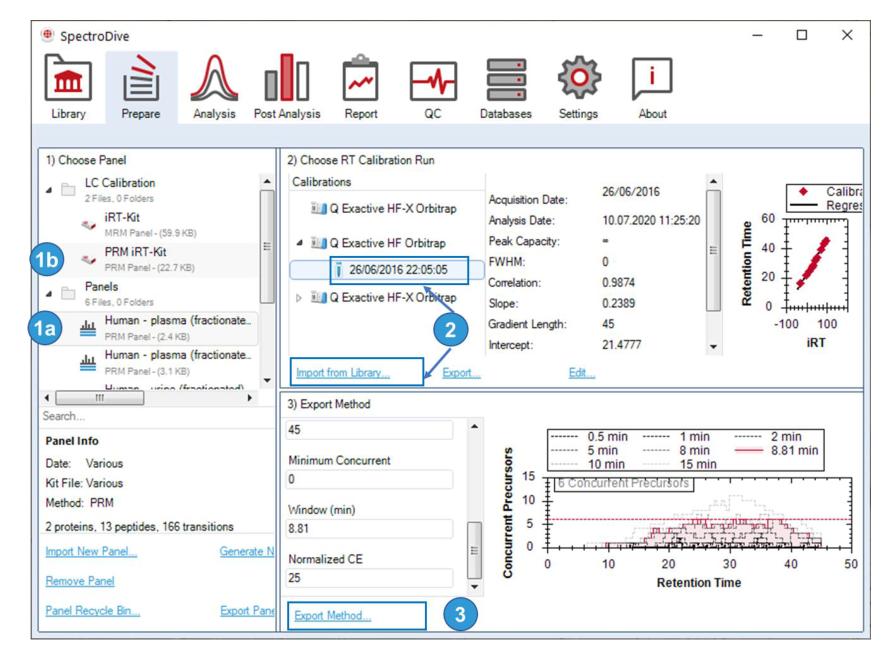
当 panel 太大、同一时间窗口内并发 transition 过多时,信噪比和 dwell time 会受到压力。split panel 不是多做一步麻烦事,而是确保方法可执行、可灵敏、可稳定的基础设计。
线性、非线性、library-based calibration 和 DIA-based calibration 的选择,决定了 method export 的时间调度是否可靠。RT calibration 的质量直接影响后续峰提取和绝对定量的可信度。
| 校准路线 | 应用前提 | 适用项目 |
|---|---|---|
| unscheduled MRM / PRM + iRT kit | 先跑包含 iRT peptides 的宽松方法,再建立线性 calibration | 最标准的入门路线,适合从零起步的 scheduled method 训练 |
| panel-based run + 线性 / 非线性 calibration | 先用宽窗口或宽松版本 panel 采一轮,再回到 Prepare 重建调度 | 更接近真实大 panel 项目,适合正式方法开发 |
| DIA-based calibration | 目标物已经包含在同色谱条件的 DIA 数据中 | 想利用 discovery / survey run 为 targeted 调度赋时 |
| library-based calibration | 已有同色谱条件下生成的 DDA / DIA spectral library | 有稳定历史库和成熟平台时,最快进入 scheduled method |
Split… 把它分成若干子 panel,并按 iRT 范围均匀分配 assays;若 panel 含 decoys,它们会被复制到每个 split 中。Generate Modified Panel 则允许从已有 panel 中更细地选择 precursors / transition groups,或重新定义 labelled channels。也就是说,modified panel 更像“精修方法版本”,不是简单复制一份 panel。PeptideResponseFactor 和 ProteinScalingFactor;采集完成后即可在 Analysis 中看到绝对量,并在 Report 里导出 EG.AbsoluteAmount 和 EG.ProteinAbsoluteAmount。Advanced
Prepare 末尾加入 SureQuant,是为了说明 SpectroDive 不仅支持常规 scheduled PRM / MRM,也支持更复杂的 triggered acquisition 思路。
重点不在于记住这个名字,而在于理解它如何利用 reference channel 或触发逻辑,在复杂基质和低丰度目标物条件下提升 targeted acquisition 的有效性。
panel generation、split、RT calibration、method export 和 SureQuant 本质上回答的是同一个问题:如何把目标物变成一套能在仪器上稳定运行的方法。
先导出并采集一套 SureQuant survey method,让 reference channel 和目标物在真实样本里先“探路”。
回到 Analysis 中查看 survey run,根据真实 peak 行为决定触发阈值,而不是凭经验拍脑袋设默认值。
把触发阈值、panel 和仪器兼容条件一起固化成最终方法,再进入正式样本采集。
| SureQuant 元素 | 模块职责 | 学生应如何理解 |
|---|---|---|
Survey Run |
先测参考通道和触发行为,再决定正式 acquisition | 它不是多余预实验,而是正式方法设计的一部分 |
Peak Fraction |
定义触发高分辨 MS2 的阈值比例 | 默认值只是起点,必须随 panel 大小和样本复杂度优化 |
TargetMass / TargetMassTrigger |
导出为最终 method folder 中的核心文件 | 说明 SureQuant 最终交付的是一套结构化方法包,而不是单个参数 |
Settings → Global → SureQuant 中最重要的参数是 Peak Fraction,它定义 mono-isotopic peak height 的百分比阈值,用于触发高分辨 MS2 扫描。1% 可作为默认起点,但必须随 panel 大小优化。Next Steps
最好的顺序是先完成 panel 与方法开发,再立刻进入 Analysis 课程,学习 calibration curves、review、panel refinement 和 iRT refinement。
继续学习 targeted analysis、绝对定量、refinement 与 review。