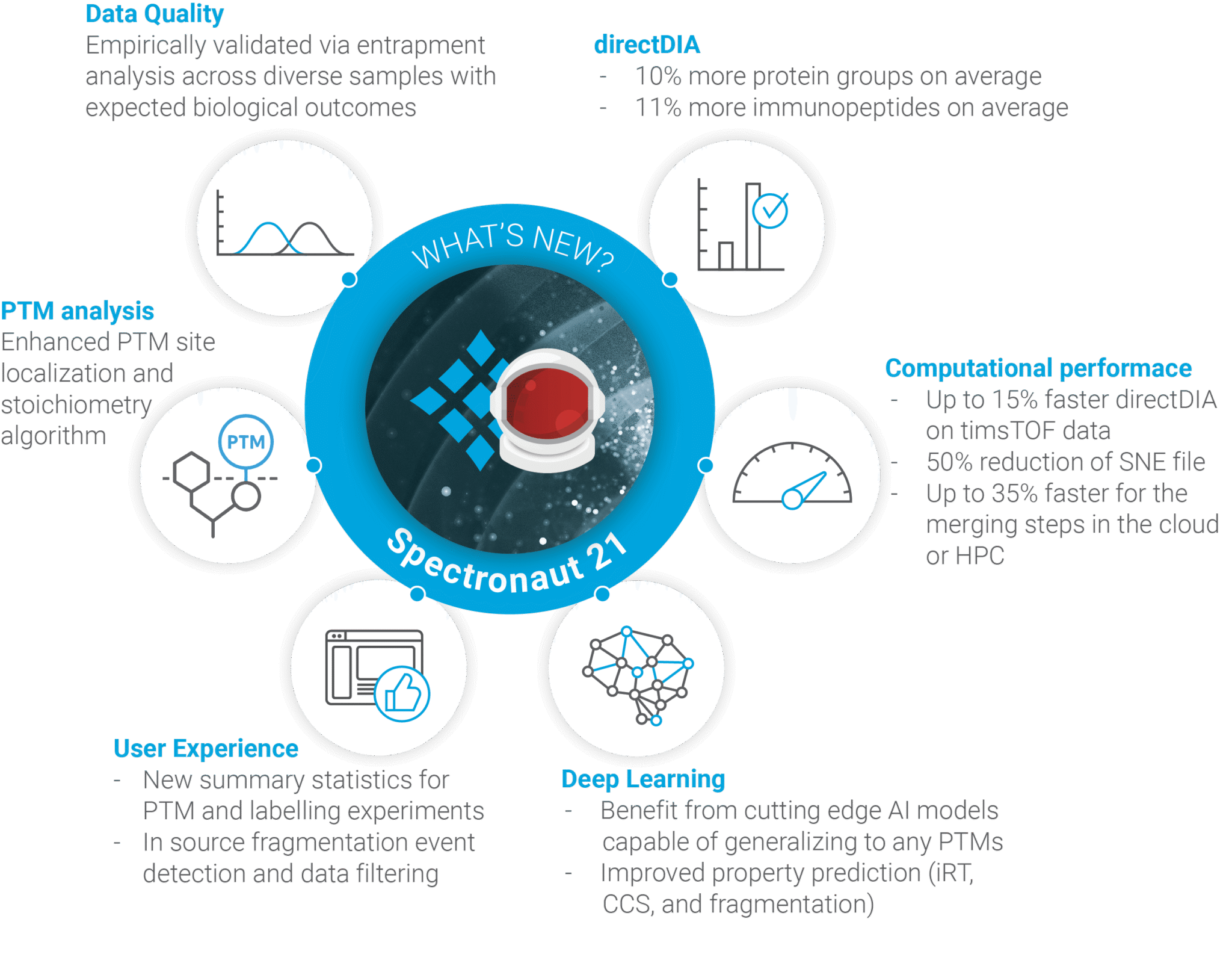
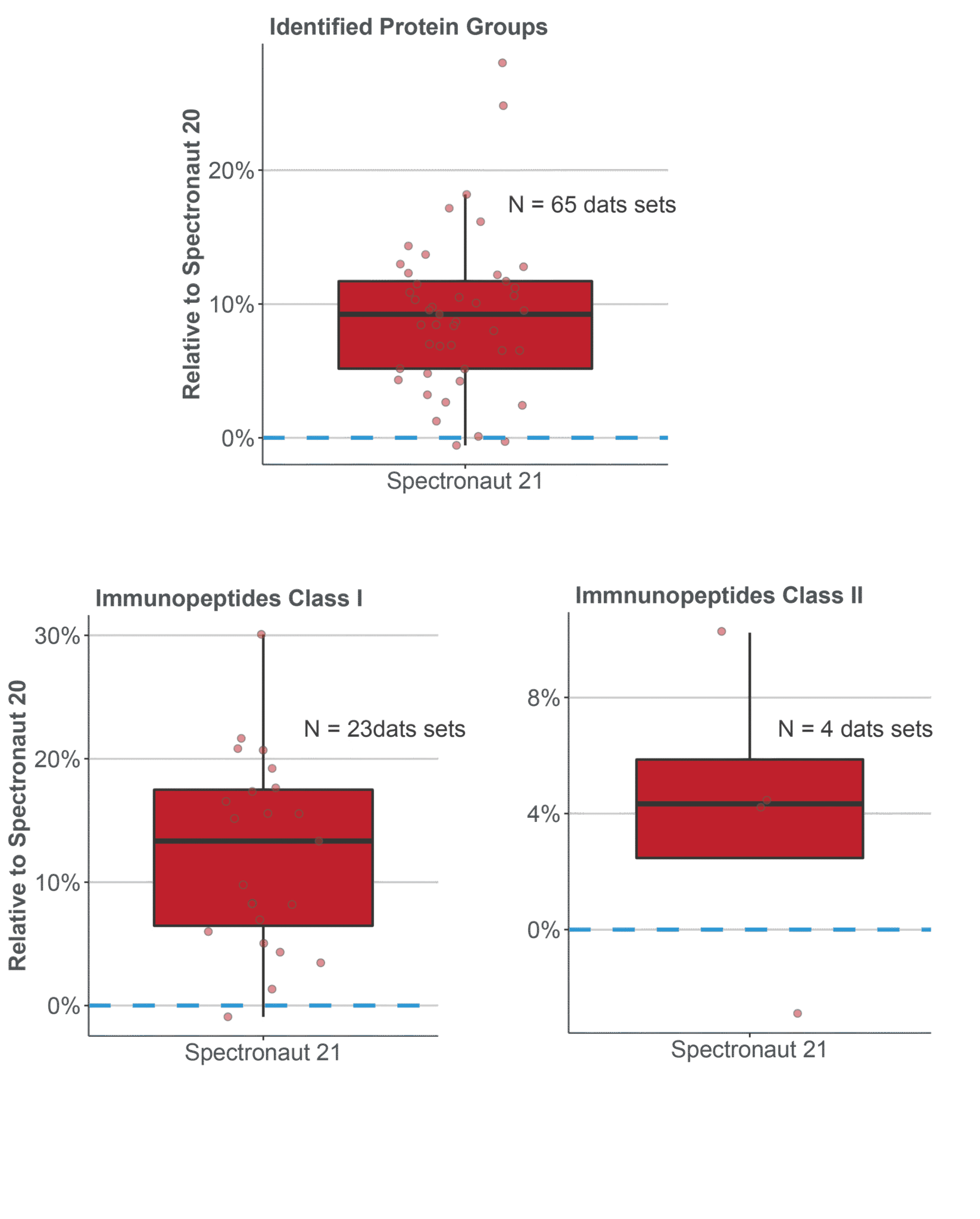
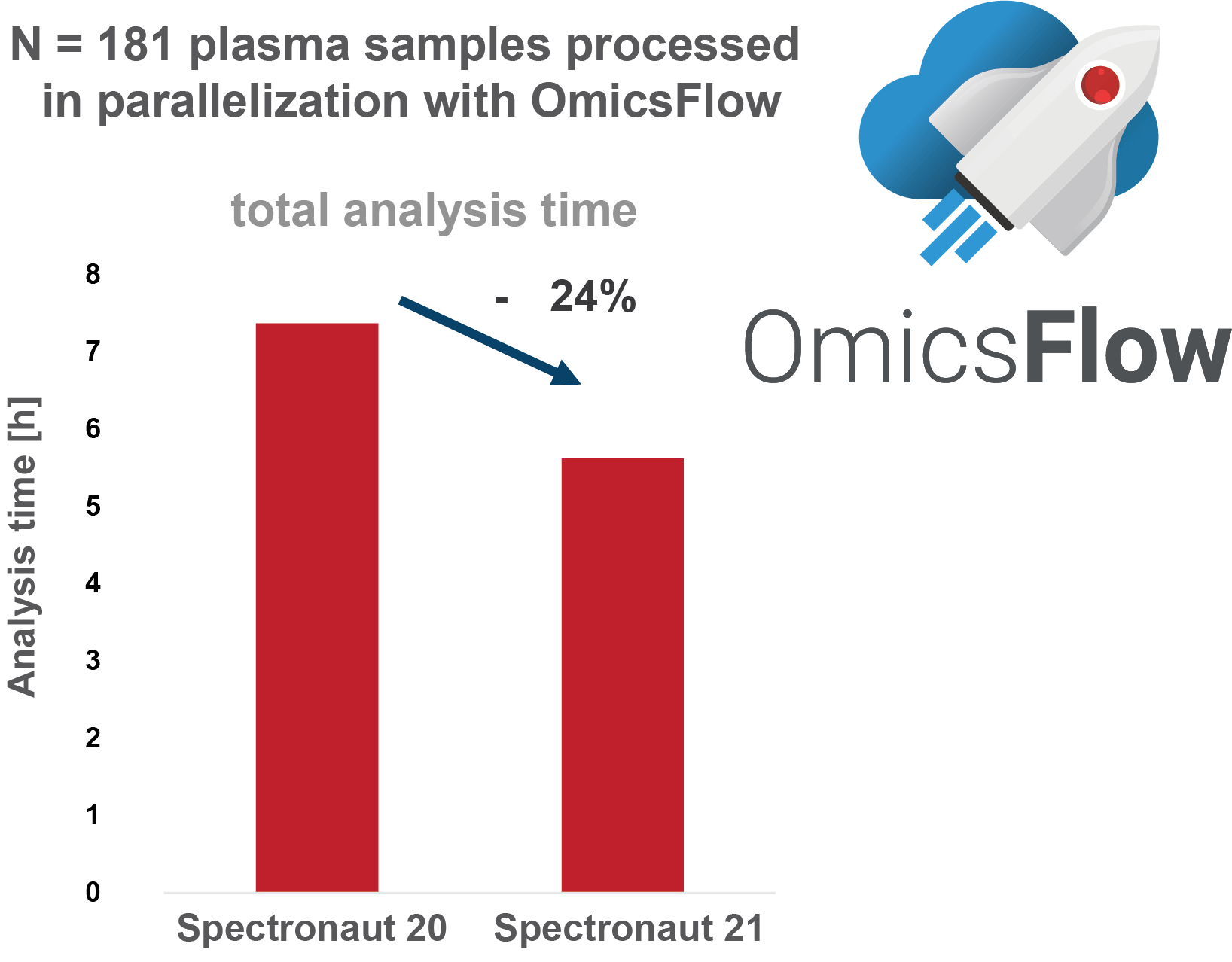
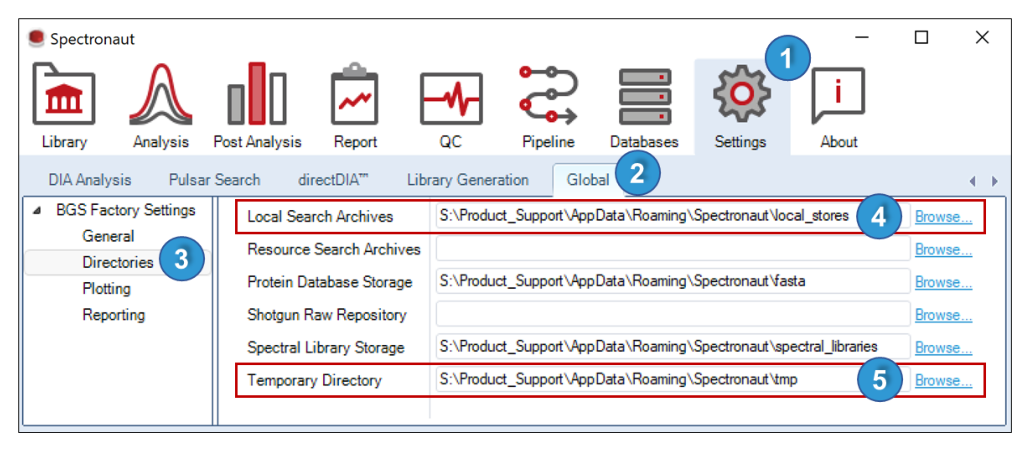
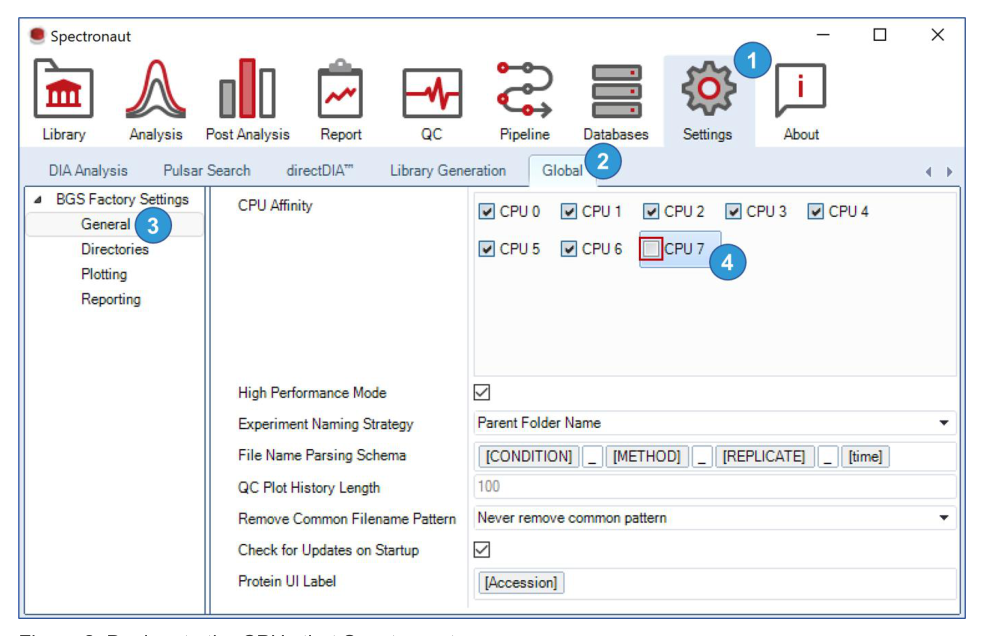
数据采集方式决定后续 workflow。DIA、PRM with MS1、labeled workflow、plexDIA、PTM workflow 和 directDIA 的输入、统计结构和报告字段不同。
功能条目 1:DIA 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 2:library-based DIA(操作场景 2) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 3:library-based / DIA 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 6:plexDIA(操作场景 6) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 7:PTM workflow(操作场景 7) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 9:HTRMS 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 10:directDIA(操作场景 10) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 12:labeled workflows(操作场景 12) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 14:PTM workflow(操作场景 14) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 15:DIA(操作场景 15) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 16:DIA / XIC 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 17:directDIA(操作场景 17) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 18:PRM with MS1(操作场景 18) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 19:labeled workflows(操作场景 19) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 20:plexDIA(操作场景 20) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 21:PTM workflow(操作场景 21) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 26:labeled workflows(操作场景 26) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 28:DIA / Pulsar 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 29:Pulsar / DIA 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 30:library-based DIA(操作场景 30) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 31:Library / directDIA / DIA / Single CV Multi CV Standard Library 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 33:DIA / directDIA 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 34:plexDIA(操作场景 34) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 35:PTM workflow(操作场景 35) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 36:DIA(操作场景 36) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 37:library-based DIA(操作场景 37) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 38:Pulsar 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 40:Library / Pulsar 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 41:plexDIA(操作场景 41) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。
功能条目 42:PTM workflow(操作场景 42) 需要作为本节的功能点核对。使用时重点确认它对应的入口、输入来源、设置含义、输出文件或图谱,以及是否与当前项目的 run、condition、library、FASTA、settings 和 report schema 保持一致。