
与 label-free DIA 的差别
label-free DIA 主要在 run 间比较样本;plexDIA 则把多个 biological states 压缩进同一 run,使 run-level 变异被显著削弱,跨通道比较更直接。
plexDIA
plexDIA 把多通道标记与 DIA 采集结合起来,在保持高数据完整性的同时提高样本通量,并把同一 run 内的跨通道比较直接带入差异分析、周转分析与低输入实验。在 Spectronaut 中,核心不是“多出几个通道”,而是 channel sets、cross-channel quantification、channel-specific FDR、heavy/light transition 选择和报表字段如何共同决定最终结论。
全站检索
全站检索会列出 plexDIA、channel-specific FDR、ChannelQ、turnover 与 labeled workflow 的相关节选,点击后直接进入对应章节。
Definition
plexDIA 将非等重标签、多通道 DIA 与统一的峰提取和打分结构结合在一起。它带来的核心变化不是“在同一个 run 里测更多样本”,而是 同一 elution group 可以在多个 channel 中同时拥有共享证据和独立定量证据,因此数据完整性、跨样本对比和时间序列设计都可以明显改善。
label-free DIA 主要在 run 间比较样本;plexDIA 则把多个 biological states 压缩进同一 run,使 run-level 变异被显著削弱,跨通道比较更直接。
plexDIA 不是 reporter ion 读数,而是保留 MS1 / MS2 色谱行为与碎片信息。结果并不依赖单个 reporter channel,而是依赖整套 cross-channel peak extraction 与 scoring。
普通 spike-in 多对应 reference ratio;plexDIA 则把不同 channel 看作实验对象本身,因此 channel set 的定义直接进入条件矩阵和统计结构。
| 读数层 | label-free DIA | plexDIA |
|---|---|---|
| 比较单元 | run 与 run 之间 | 同一 run 内 channel 与 channel 之间,同时保留 run 间比较 |
| 缺失值来源 | run 间峰提取、采样与漂移共同影响 | 共享峰边界降低通道间缺失,剩余问题集中在通道特异干扰和打分层 |
| 典型场景 | 大队列 discovery、常规组织与体液 | 低输入、多时间点、turnover 和希望提高样本通量的 discovery 设计 |
Nature Biotechnology 的原始文献给出的结论非常明确:plexDIA 在同等仪器时间下可把蛋白组通量提升约 3 倍,在此前每个样本大约测到 5,000 个蛋白的条件下提升到接近 8,000 个蛋白,并在单细胞场景中实现约 1,000 个蛋白和 98% 的数据完整性。这些数字说明 plexDIA 的价值首先体现在 throughput 与 completeness,而不是单纯“命中数更多”。
图中把标记、channel set、共享峰边界、通道级过滤和 turnover 读数组织成一条完整链路。点击节点可直接跳转。
Spectronaut
在 Spectronaut 中,plexDIA 不靠额外脚本拼接,而是直接进入 labeled workflow、conditions 与 report 结构。真正需要记住的是: 先在 DIA Analysis Settings 里把 multi-channel 数据解释为 labeled workflow,再在 Condition Setup 里定义 run condition 与 channel set。light / medium / heavy 这些标签不只是列名,它们是 channel sets 的组成部分,决定跨通道定量、pairwise ratio 和后续 differential analysis 的语义。 如果前置 workflow 仍被解释为 Force Label free,或 From Library Annotation 没有有效 channel annotation 且 fallback 方向错误,Condition Setup 只能定义样本条件,不能把单个 precursor 重新变成多通道 elution group,也不会生成正确的 channel quantity 与 ratio 结构。
| 设置位置 | plexDIA 中要确认什么 | 判断标准 |
|---|---|---|
| DIA Analysis Settings → Workflow | Multi-Channel Workflow Definition 选择 Labeled,或使用带 workflow annotation 的谱库并把 fallback 设为 Labeled。 | peak detection 与 scoring 会作用于所有 channels,后分析才会把 channel ratio、channel set condition 和 run condition 组合起来。 |
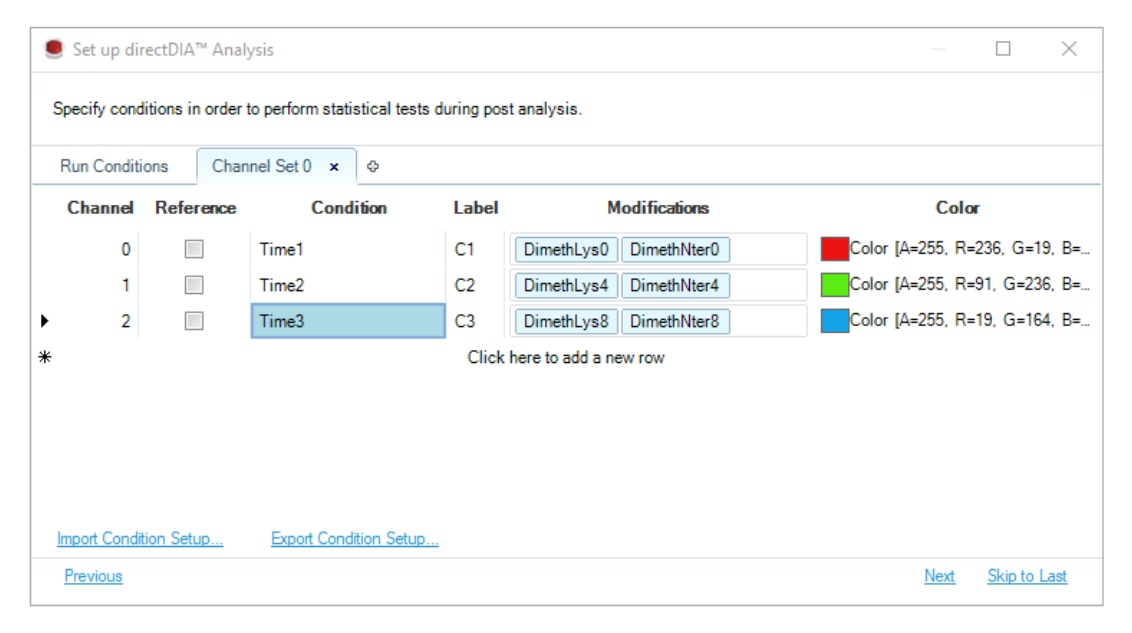
| Labeling / channel annotation | 在进入 Condition Setup 前,确认 light / medium / heavy 或 A / B / C 等 channel 的 label 与 modification annotation 已经进入谱库或 analysis schema。 | Channel Set tab 中每个 channel 都能显示明确的 Label 与 Modifications;如果这里只剩一个普通 label-free precursor,后续 conditions 无法补回 labeling 语义。 |
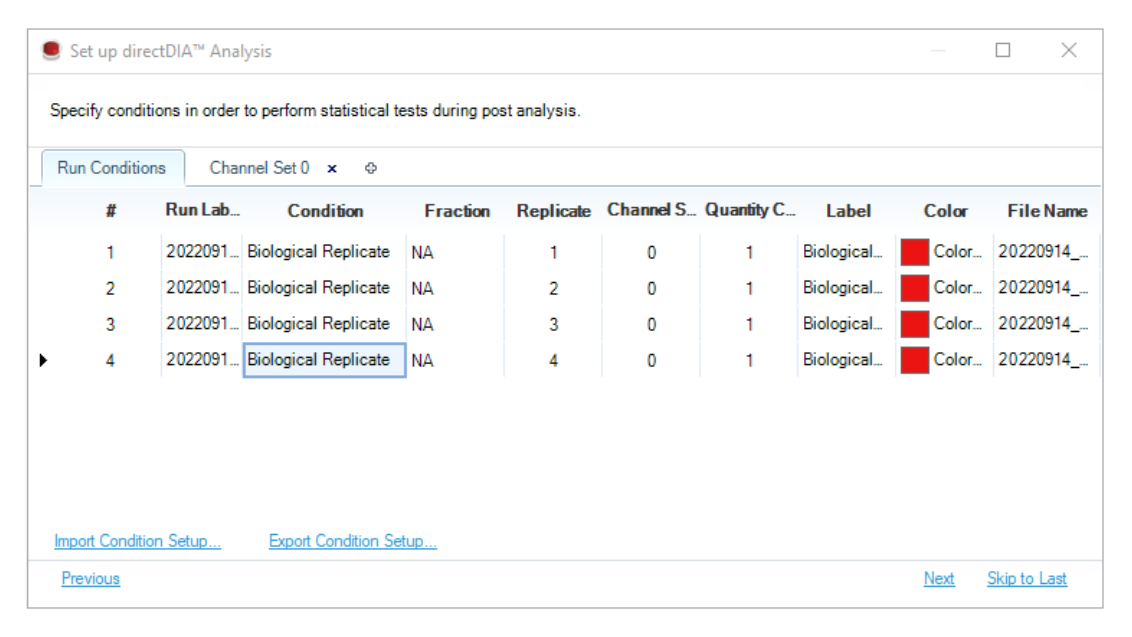
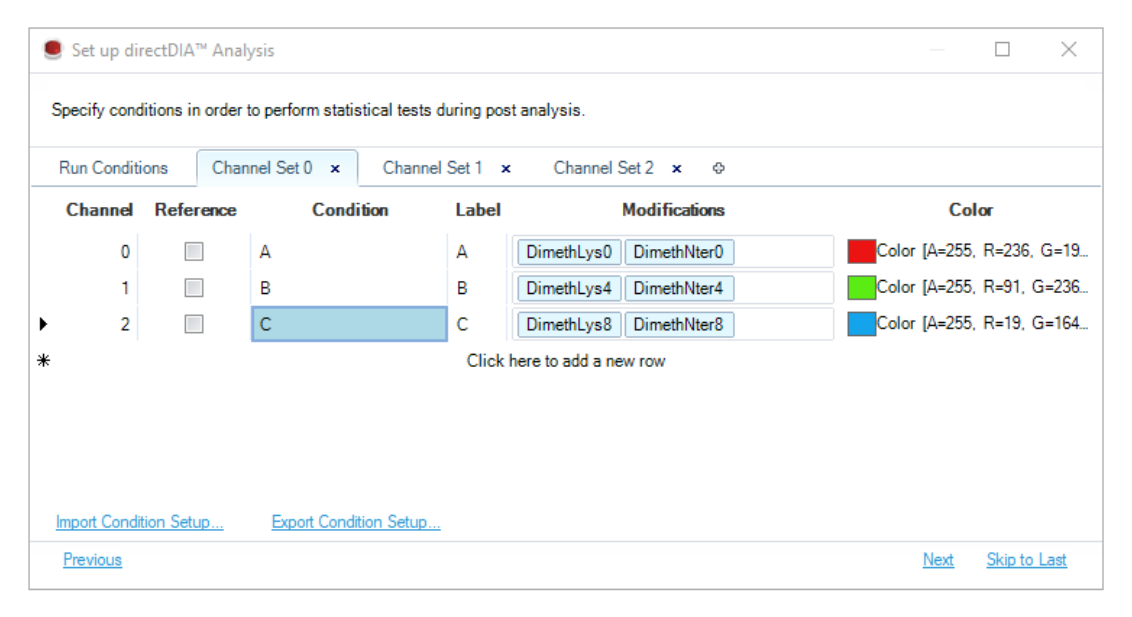
| Run Conditions | 给每个 run 指定 biological replicate、run-level condition、fraction、所属 channel set 与条件显示标签。 | 固定标签设计通常只有一个 channel set;label permutation 设计需要多个 channel sets。Run-level 的 Is Reference 用于运行层面的比较语义,不等同于 Channel Set 内部的 reference channel。 |
| Channel Set tab | 逐行定义每个 channel 的 biological condition、通道 label、modifications、reference 与颜色。 | 同一个 run 内的 channels 才会被解释成不同时间点、处理组或 heavy/light ratio 对象;这里的 Reference 描述 channel set 内部的参考通道或 ratio 方向。 |


FDR & Filtering
Biognosys 在 HUPO 2024 与 Spectronaut 20 的官方资料中,把这条线讲得非常清楚:plexDIA 真正的难点不是“如何把多通道数据读出来”, 而是如何在共享峰边界的同时保持每个 channel 的独立可信度与定量精度。为此,channel-specific FDR 和 deep-learning assisted heavy/light transition selection 成为 Spectronaut 20 的核心升级点。
把所有 channels 当作一个整体,只要整体 elution group 通过,就保留全部 channel。覆盖最高,但更偏向整体定量轮廓,不直接承担严格的通道级差异结论。
MinQ 要求至少一个 channel 独立通过 q-value 门槛,更偏向保留可定量对象;MaxQ 要求样本中的全部 channels 都通过门槛,是更保守的通道级过滤。两者分别对应 sensitivity 与 precision 的取舍。
ChannelQ 把每个 channel 独立过滤,只保留该 channel 自身可信的定量结果。它直接对应 turnover、time-course 和 channel-level QC。
这张图不是性能排行榜,而是不同过滤策略在覆盖度、通道独立性与保守程度上的取舍关系。
| 设置层 | 作用 | 什么时候必须关注 |
|---|---|---|
| channel-specific FDR | 保证共享峰边界下每个 channel 仍有独立的可信度控制 | 多时间点、turnover、通道间强弱差异大时 |
| heavy/light transition 选择 | 避免通道间同位素干扰把 transition 直接带偏 | 重轻通道 overlap 明显、低输入和复杂基质时 |
| minimum log2 precursor quantity | 过滤掉量级过低、无法稳定进入 ratio 计算的对象 | 需要稳定 fold change 或 turnover readout 时 |
| common workflow settings | 统一不同通道与不同时间点的 extraction 与 scoring 基线 | 跨 run、跨时间点比较时 |
Biognosys 官方在 ASMS 2024 和 HUPO 2024 的表述是一致的:Spectronaut 19 / 20 对 large and complex multiplex DIA datasets 的支持,不是把 labeled workflow 当成附录功能,而是通过 channel-specific FDR、transition 选择和报表字段,把 multiplex DIA 提升到正式 discovery 与 turnover 分析层级。也正因为如此,plexDIA 需要和 FDR、QC、report schema 一起学,而不是只停在 channel setup。
Turnover
Biognosys 在 HUPO 2024 lunch seminar 和 Spectronaut 20 官方资料里多次强调,与 Yansheng Liu 团队合作的重点并不是再做一条 labeled workflow, 而是把 multiplex-DIA 直接推向 proteome-wide turnover rates。这里最关键的两项实现分别是 channel-specific FDR,以及面向 heavy / light 对的 deep-learning transition selection。
Biognosys 在 ASMS 2024 新闻中引用 Yansheng Liu 的说法:Spectronaut 19 已能在不牺牲数据完整性的前提下,高效分析每个 run 含有数万条肽段定量结果的 multiplex proteomics 数据,从而推进真实蛋白丰度与 protein turnover rates 的联合分析。这说明官方把 plexDIA 明确放到了 abundance + turnover 的双读数框架里。
Nature Communications 2025 的 multiplex-DIA 工作流在 A2780 细胞系的 4 个时间点、3 个生物学重复条件下,平均定量约 6,900 个蛋白;在 timsTOF Ultra 与 Orbitrap Fusion Lumos 的 pSILAC 跨平台设置中,平均可达约 9,130 个蛋白,并把梯度缩短约 2.5 倍。Exploris 480 与 timsTOF HT 的 dimethyl-labeling mDIA 数据则说明该思路也能扩展到 2-channel / 3-channel 标记设计。
图中把时间点与标签设计、channel-specific filtering、stable ratio matrix 三类证据汇聚到 turnover fit;箭头表示依赖关系,不代表固定处理顺序。点击节点可跳转。
| 层级 | plexDIA 要保证什么 | 否则会发生什么 |
|---|---|---|
| 通道设计 | 时间点、处理组和标签互换必须构成稳定的 channel sets | 同一 run 内 ratio matrix 失真,后续 turnover 拟合直接偏移 |
| 过滤与 transition | 每个 channel 的可信度和 heavy/light fragments 必须单独判断 | 弱通道被强通道掩盖,导致 turnover 曲线被高估或低估 |
| 报表层 | 需要保留 channel-level q-values、minimum quantity 过滤和 time-point 结构 | 导出后只剩 protein table,无法再区分真实 turnover 与 channel artifact |
Implementation
这条路线不是只有采集和软件。低输入、多时间点、多通道 discovery 要同时处理前处理稳定性、nanoLC 分离、软件过滤和最终结果交付。
多通道 low-input 设计对前处理一致性极其敏感。Auto120 / Auto150 与易肽前处理体系更容易把 digestions、cleanup 和 batch reproducibility 稳定下来。
plexDIA 需要更稳的 retention time 和更窄的峰形。Aurora Series、NanoShield 与 HeatSync 这类分离端配置,会直接影响 cross-channel extraction 与 turnover time-course 的精度。
Spectronaut 负责 labeled workflow、channel-specific FDR 与 channel-level reports;OmicsCloud 则负责结果共享、远程复核、项目留痕和最终交付。
References
下面这组资料覆盖 multiplex-DIA、Spectronaut 20、channel-specific FDR 和 turnover 的关键技术节点。
官方首次明确把 large and complex multiplex DIA datasets 与 Yansheng Liu 的 protein turnover 应用放在同一条产品升级线上。
官方明确写出两项与 Yansheng Liu 合作开发的方法:channel-specific FDR,以及 deep-learning based heavy/light transition selection。
给出三倍 throughput、约 8,000 proteins per sample、98% completeness 和单细胞 1,000 proteins 的关键边界。
给出 GroupQ / MinQ / MaxQ / ChannelQ、channel-specific filtering、minimum log2 precursor quantity 以及 turnover 应用的完整实现。
快速跳转