Appendix 1:Analysis Settings
这一部分可直接沉淀为 analysis schema 说明。extraction、scoring、workflow type 和 quantification 需要放进同一条解释链。
SpectroDive Appendix
Appendix 1-8 与 Glossary 组织成“读图、读字段、读设置”的附录模块。 附录不只是正文后的补充,而是参数、图谱、字段与术语解释层。
Orientation
正文章节更多定义流程与对象,附录则集中处理提取与打分逻辑、图形判读、字段解释和术语框架。
Appendix 1-4
附录前四章更像 SpectroDive 的“参数底稿”。它们分别回答四个问题:分析是怎么计算的、panel 来源是怎么来的、library generation 如何约束搜索空间、全局环境怎样影响所有项目。
这一部分可直接沉淀为 analysis schema 说明。extraction、scoring、workflow type 和 quantification 需要放进同一条解释链。
这里解释 SpectroDive 如何和 Pulsar 建库能力衔接,直接对应 panel 来源和搜索空间管理。
这里解释 fragment 选择、label 逻辑和过滤规则如何影响 panel 信息来源。
这一部分可直接配合 Settings 模块使用,把 defaults、directories、parsing 和 method export 固化成 SOP。
Appendix 5-6
这两部分非常适合放到上机后复盘里。前者对应读图能力,后者对应动作含义。很多人知道右键能点什么,却不知道 Accept、Reject、Refine 和 Re-extract 这些动作到底会如何影响 panel 和结果结构。
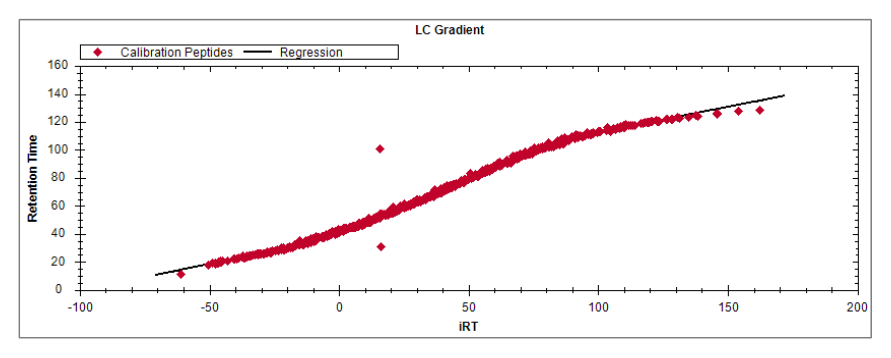
真正的靶向判断往往就发生在这些图里,而不是发生在汇总表里。只看 quantity 而不回看图,是最常见也最危险的捷径。
因为这些右键动作决定的是 panel 是否真的被更新、SureQuant / HybridDIA 是否真的重提取、review 判断是否被真正提交。它们是从“看结果”走向“改方法”的关节。
Appendix 7
Appendix 7 的价值在于,它把 overview、data completeness、CV、heatmap、volcano 等图真正解释开了。这一部分可直接与 Reporting 模块联动:先在 Reporting 里明确这些图的作用,再在附录页里处理读图。
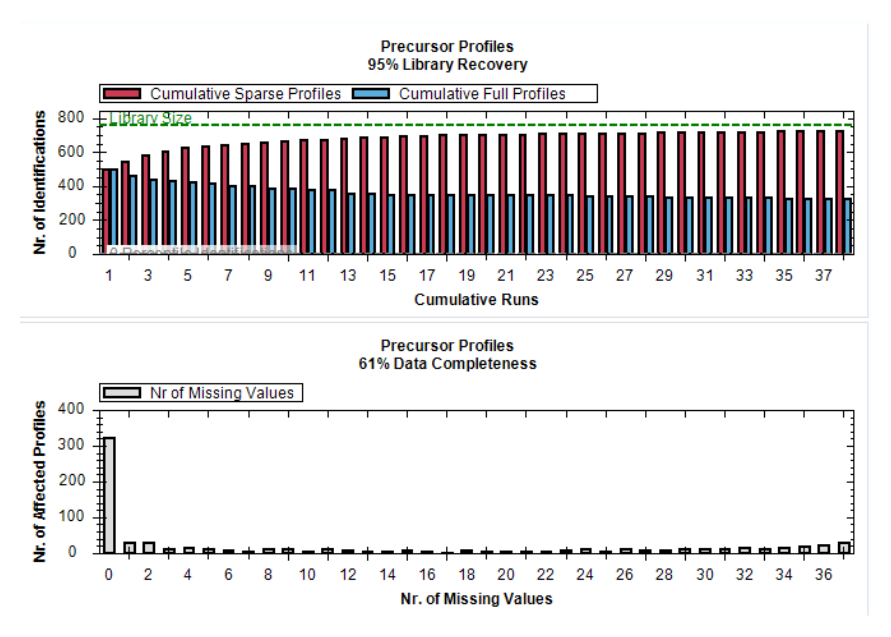
CVs Below X,判断不同层级对象有多少落在 ≤10% 或 ≤20% CV 区间。Appendix 8
Appendix 8 几乎天然就是“字段解释卡片”。Protein、Peptide、Elution Group、Transition Group 各层哪些字段最关键、哪些字段不明显却高价值,都可以在这里集中组织。
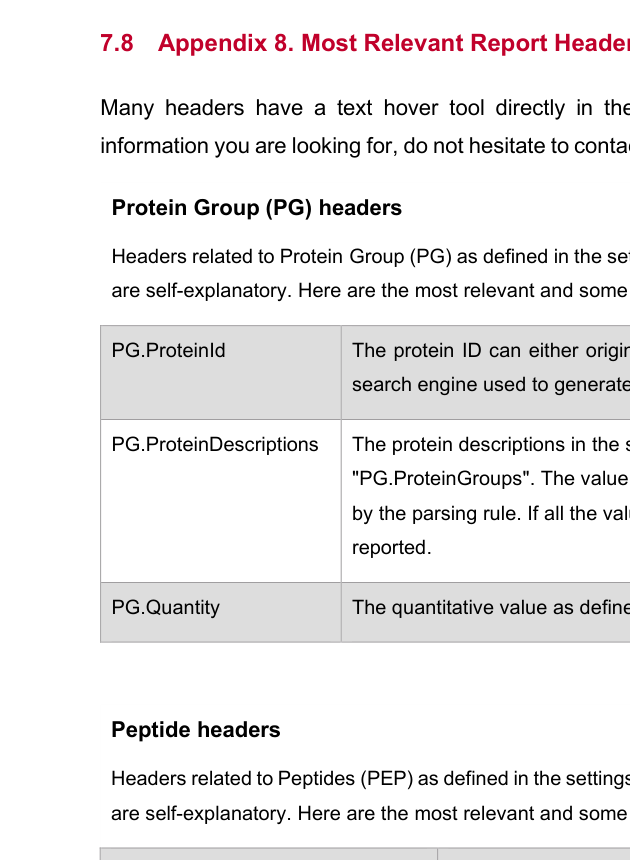
PG.ProteinId、PEP.GroupingKey、EG.PrecursorId、TG.IntMID。EG.Qvalue、EG.Cscore、EG.IsUserPeak、EG.Verified、EG.MeanTailingFactor。EG.AbsoluteAmount、EG.AbsoluteAmountRangeLimitted、EG.LLOQ、EG.ULOQ、EG.LOD。TG.CompensationVoltage、TG.MS1MonoIsotopicHeight、T.Quantity,它们更贴近 FAIMS / high-end PRM 和 transition-level review。Glossary
如果新人能很快分清 MRM、PRM、Scheduled MRM、tMRM、Assay Panel、Spectral Library、Dwell Time、Duty Cycle、Cycle Time、FDR 和 q-value,那么后续学 Prepare、Analysis 和 Reporting 的速度会明显快很多。Glossary 的价值就在于建立这套共同语言。

Next Steps
如果这里主要在查图和查字段,下一步可回到 Reporting 模块继续处理 report schema 与字段解释;如果主要在查 settings 和 glossary,下一步则进入 Settings 模块,把附录里的解释重新接回到默认模板与命令行能力上。
继续处理 Post Analysis、report schema 和 Appendix 8 字段解释。
继续处理 defaults、command line 和 glossary 解释。