Reporting 的核心作用
靶向验证的业务价值体现在指标能否被解释、追踪、纳入 SOP 报告并对接临床或药效模型。这些问题都集中在结果解释与交付层解决。
SpectroDive Reporting
这里覆盖 Post Analysis、Report Perspective、Quality Control、
schema design、field interpretation 与 absolute quantification output,
对应 SpectroDive 的解释、报表与交付主线。
Orientation
PRM / MRM 分析完成后,工作并不会止于导表。Post Analysis 对应全局质量,Report Perspective 对应结构化交付,QC Perspective 对应长期运行视角,Appendix 8 对应字段级解释语言。
靶向验证的业务价值体现在指标能否被解释、追踪、纳入 SOP 报告并对接临床或药效模型。这些问题都集中在结果解释与交付层解决。
| 层级 | 最核心的问题 | 主要输出 |
|---|---|---|
Post Analysis |
这批数据值不值得被解释 | overview、completeness、CV、scoring 和差异结构的整体判断 |
Report Perspective |
要把哪些对象和字段正式交给别人 | schema、preview 和结构化导出模板 |
QC Perspective |
这次结果放到长期运行里是否仍然稳定 | instrument-specific history 和长期趋势 |
Appendix 8 |
每个字段究竟在说明什么 | 身份字段、质量字段、绝对定量边界字段的统一解释语言 |
把 Post Analysis、Report、QC、header dictionary 和绝对定量交付串起来的解释结构。
Post Analysis
进入字段和报表之前,需要先确认分析是否稳定、数据完整性是否足够、scoring histograms 是否合理,以及差异比较是否形成清晰结构。Overview、identifications、data completeness、CV 与 normalization 共同承担这一层判断。
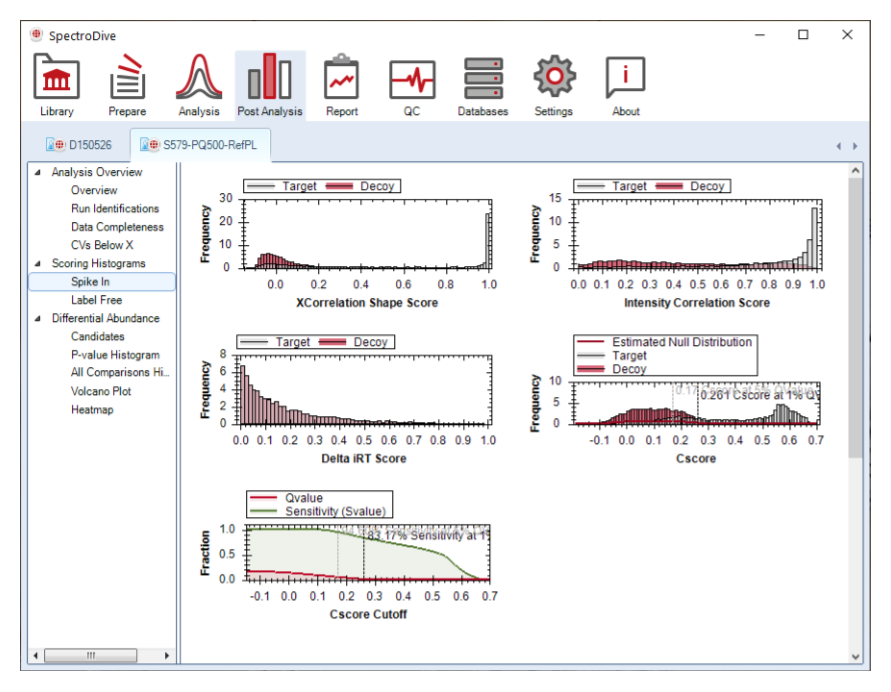
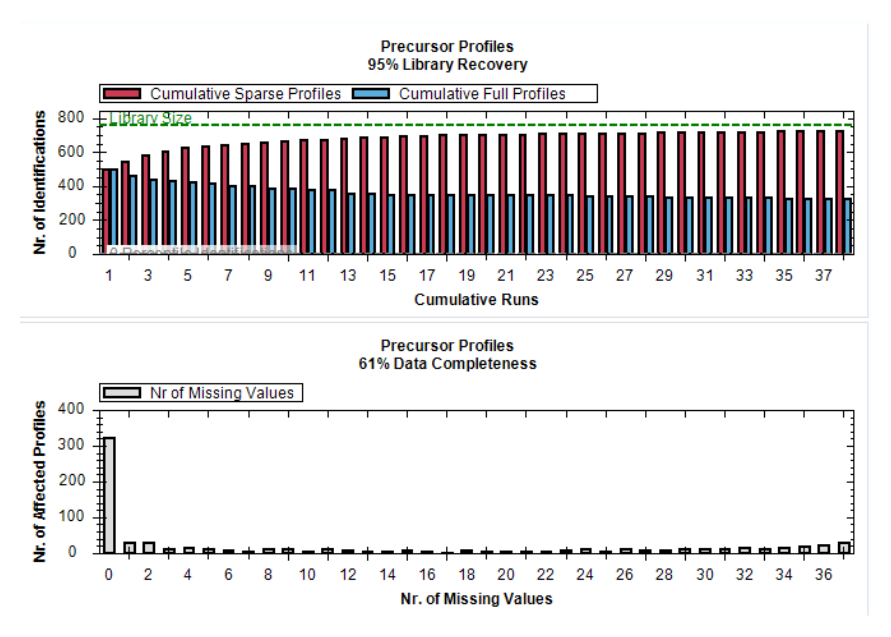
identifications、data completeness、CV 与 normalization 一旦不稳定,后续所有统计结果都会失去高置信度基础。Post Analysis 的第一层任务因此是建立质量门槛。
scoring histograms 既是软件评估指标,也对应识别质量、分数分布和目标物区分度。它比直接查看显著性表更接近方法学判断。
| 图层 / 面板 | 优先检查 | 如果异常,意味着什么 |
|---|---|---|
Overview / Identifications |
整体命中数量、是否有明显 run 间断层 | 可能是方法不稳、panel 过大、样本质量或采集设置异常 |
Data Completeness |
缺失值结构是否集中在某些 run 或某些条件 | 提示 scheduled window、峰提取或样本基质对特定 analyte 不友好 |
CV / Normalization |
重复内波动是否合理、归一化前后是否改善 | 若 CV 偏高,后续所有 differential abundance 都应更谨慎 |
Scoring Histograms |
target / decoy 或 spike-in 分布是否分离 | 若分布不清晰,说明 score、peak picking 或 panel 质量需要回查 |
Differential Abundance |
volcano、heatmap、比较方向是否符合实验设计 | 如果全局结构异常,很可能前面的质量层已经埋下问题 |
Report Perspective
Schema tree、Column chooser、Filters 与 Preview 共同定义报表结构的设计、保存、复用与标准化管理方式。
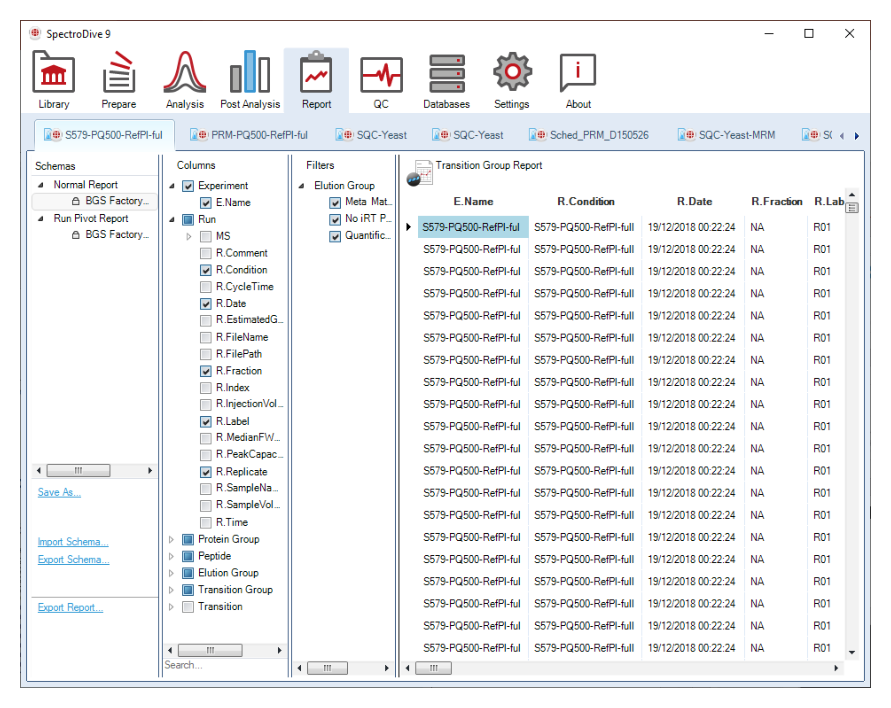
Schema tree 用来存放内置或自定义报表模板;Column chooser 决定字段集合;Filters 控制筛选条件;Preview 用来在正式导出前检查结构是否符合预期。这套结构可以稳定承接 discovery 转 targeted、项目交付、绝对定量汇总等不同模板。
Normal Report 对应 long-format 分析、数据库入库与脚本处理;Run Pivot Report 对应人工浏览、Excel 展示与固定格式输出。
| 报表结构 | 主要用途 | 使用边界 |
|---|---|---|
Normal Report |
long-format 统计、数据库入库、二次脚本处理 | 不宜只靠人工肉眼快速横向查看所有 runs |
Run Pivot Report |
Excel 浏览、人工审核、固定模板展示 | 不宜作为复杂统计和长期数据库的唯一输入 |
自定义 schema |
项目报告、绝对定量汇总、QC / review 模板 | 不宜每次项目都从零临时拼接 |
Quality Control
QC Perspective 基于 iRT reference peptides,并会自动为不同仪器建立独立 QC history。QC 在这里承担长期运行监控系统的角色。
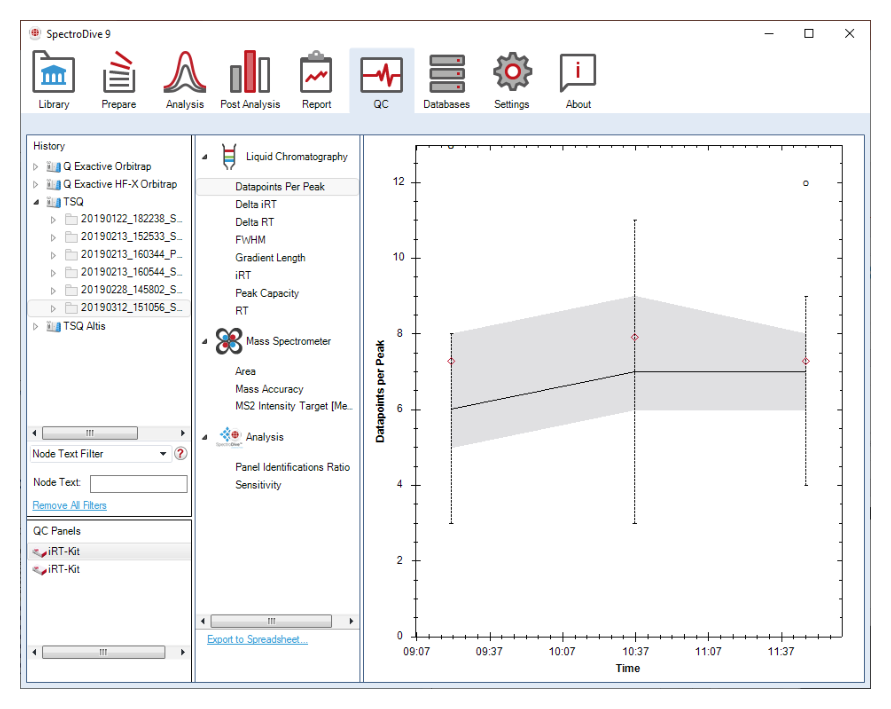
iRT kit 同时连接色谱性能、保留时间稳定性与分析设置自动校准,因此 QC 会同时监控 LC、MS 与软件分析层。
同型号多台仪器时需要手动命名,并按实验室既有 QC 结构建立文件夹层级。这直接解决跨时间、跨仪器与跨项目的可追踪性。
| QC 维度 | 它回答的问题 | 沉淀形式 |
|---|---|---|
| iRT / RT 稳定性 | 色谱是否漂移、调度窗口是否还可靠 | 方法放行标准和维护阈值 |
| instrument-specific history | 这次 run 放到长期趋势里是否异常 | 平台仪器历史档案 |
| QC 目录与命名 | 多台仪器、多套 kit 的结果能否长期追踪 | 实验室统一 QC 文件结构 |
Appendix 8
Appendix 8 是靶向验证的字段字典,覆盖对象身份、peak / score / review 质量,以及绝对定量是否落在可报告区间内三类问题。
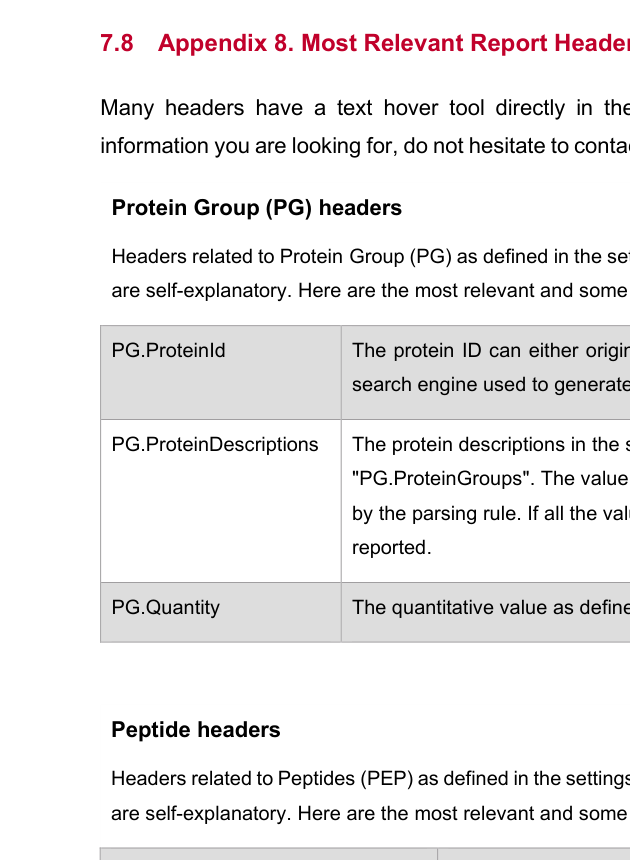
| 字段 | 中文解释 | 关键解释点 |
|---|---|---|
PG.ProteinId / PG.ProteinDescriptions | 蛋白身份与描述字段 | 属于交付层主键,决定结果到底指向哪个蛋白或蛋白组 |
PG.Quantity | 蛋白层定量值 | 必须先理解 settings 中定义的 quantity 规则,再解释这个值 |
PEP.IsProteotypic | 该 peptide 是否只对应一个蛋白 | 对应 biomarker 验证与 panel 设计中的身份限定 |
EG.Qvalue / EG.Cscore | 识别置信度和评分字段 | 应与峰型、人工 review、transition 选择一起判断,而不是孤立看分数 |
EG.AbsoluteAmount | 绝对定量结果 | 只有在 calibration curve 建立正确且结果落在可量化区间内时才进入正式报告 |
EG.AbsoluteAmountRangeLimitted | 线性范围限制后的绝对量 | 对应“有数值但仍不直接进入正式报告”的情况 |
EG.LLOQ / EG.ULOQ / EG.LOD | 定量下限、上限和检测下限 | 要明确区分“能检出”和“能稳定定量” |
EG.MeanTailingFactor | 峰拖尾相关指标 | 对应峰型质量,而不是只看面积大小 |
TG.CompensationVoltage | FAIMS-PRM 等高级场景下的补偿电压 | 说明 panel 与仪器 method 在高级工作流中是强耦合的 |
| 字段层级 | 优先字段 | 它们主要服务什么判断 |
|---|---|---|
Protein Group / Peptide |
ProteinId、Quantity、IsProteotypic |
身份归属和 biomarker 解释是否站得住 |
Elution Group |
Qvalue、Cscore、AbsoluteAmount、LLOQ / ULOQ / LOD |
峰质量、识别置信度和绝对定量边界 |
Transition Group |
CompensationVoltage、Quantity |
高级 workflow 和 method-level 解释 |
AbsoluteAmount 当成无条件可信结果,而忽略 LLOQ / ULOQ / LOD。PG.Quantity 而忽略底下 peptide / elution group / transition 的证据质量。proteotypic 与非 proteotypic peptide,就直接做 biomarker 解释。Next Steps
这里继续进入 Settings,处理 schema、file name parsing、method export defaults、command line 与 glossary。
继续处理 settings schema、global defaults、command line 与 glossary。
切换到连续阅读页面,按完整文本顺序展开 Reporting 与 QC。
Absolute quantification、review 与 refinement 对应主分析页。