本课定位
因为很多团队会直接跳到 report schema 或字段解释,但如果不先判断 data completeness、CV、normalization 和 scoring 分布,后面导出的任何表都可能建立在一个并不稳定的矩阵上。
SpectroDive Post Analysis
Post Analysis 承接 Reporting 体系中的结果解释部分,重点覆盖
Analysis Overview、Scoring Histograms、
Differential Abundance、Data Completeness、
Coefficient of Variation 和 Normalization。
先判断结果矩阵是否具备解释基础,再进入 report schema 和字段交付层。
Orientation
Post Analysis 被定义为 summary information、Scoring Histograms 和 Differential Abundance 的集合。这种结构天然对应三层判断:先看总体质量,再看识别评分,再看差异结果。
因为很多团队会直接跳到 report schema 或字段解释,但如果不先判断 data completeness、CV、normalization 和 scoring 分布,后面导出的任何表都可能建立在一个并不稳定的矩阵上。
Post Analysis 对应结果解释,Reporting 对应结果交付。两部分内容分别处理矩阵结构、字段组织和最终输出。
从 overview、scoring、矩阵质量到差异结果解释的学习流。
Post Analysis Perspective 会同时报告三类内容:一是 Analysis 的 summary information,二是 Scoring Histograms,三是 Differential Abundance 结果。这个顺序的含义是,SpectroDive 并不鼓励一进来就看候选表,而是先看 experiment-wide 的整体状态,再看识别分数分布,最后才看显著差异对象。
这也决定了后分析不是“统计展示区”,而是结果把关区。只有先从整体识别数、缺失值结构、CV 和 normalization 出发,才能判断某个差异结果究竟是生物学差异,还是矩阵本身不稳定造成的表观变化。
Overview
Overview 会展示 proteins / peptides identified、misscleavages、library recovery 等 experiment-wide 信息,并配套 identifications、data completeness、coefficient of variation 和 normalization 等图。这意味着 Post Analysis 的第一步不是挑候选,而是建立对实验整体状态的判断。
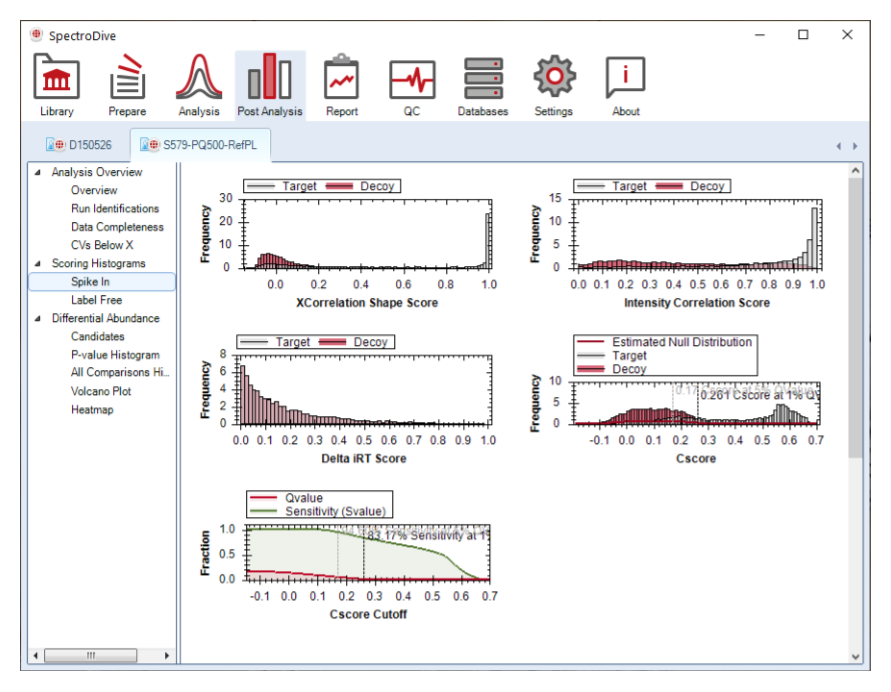
Overview 下点名了四类图:identifications、data completeness、coefficient of variation、normalization。它们不是装饰性图表,而是四个连续判断。identifications 帮你确认不同条件下到底识别到了多少 proteins / peptides;data completeness 帮你判断缺失值结构是稀疏还是系统性;CV 告诉你重复间精密度是否足够;normalization 则用于观察系统偏差有没有被合理矫正。
这些图都支持右键修改设置,详细说明放在 Appendix 7 与 Box 1 中。这说明 SpectroDive 的图并不是“只能看”,而是可以切换 context、导出矩阵、调整展示方式的分析工具。每张图都需要结合右键选项一起阅读,形成“图和参数一起读”的习惯。
Scoring
这里用 spike-in peptides 的 scoring histograms 作为示例,目的就是先把识别质量看懂。对 targeted 项目来说,这一步尤其重要,因为很多后续 refinement 决策都和识别质量直接相关。
因为它能更直观地展示已知目标物在当前分析中的分数分布,让你更容易把“理论上应该看到什么”和“当前软件识别到了什么”联系起来。
因为分布结构如果异常,再漂亮的 report schema 也只能把问题包装得更整齐,而不会让结果更可信。
这一节的核心定义非常直接:Scoring Histograms 展示的是 target 与 decoy distribution estimation 的行为,而这种行为定义了 precursor level 上的 discriminant scores、Cscores、q-values 和 sensitivity。也就是说,这里不是在看“一个好看的分布图”,而是在看软件如何区分真实目标与干扰、如何把这种区分转成识别分值和错误发现控制。
scoring histograms 会根据当前实验中存在的 workflow 分别展示。也就是说,label-free、labeled、spike-in 等 workflow 的 scoring 结构并不完全一样,这里更像“不同 workflow 在当前实验中的识别难度剖面图”,而不是统一模板图。
Matrix Quality
identifications、data completeness、coefficient of variation 和 normalization 这些图并不是次要统计,而是用来判断 targeted 数据矩阵是否可稳定解释的核心依据。
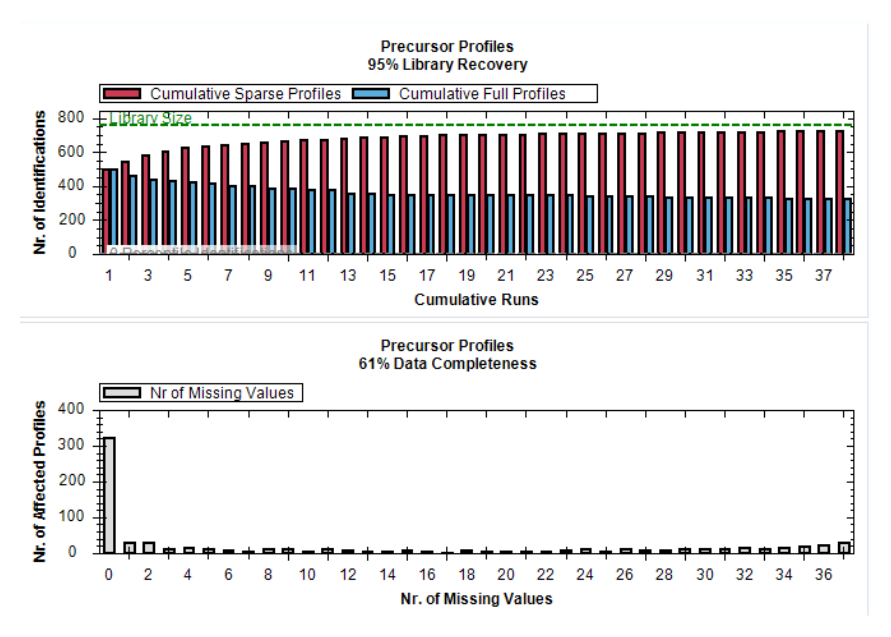
重点是先判断不同条件和不同目标物的稀疏程度,再判断是否存在系统性缺失。这样比直接进入差异分析更能建立“矩阵视角”。
CV 帮你看组内稳定性,Normalization 帮你看系统偏差是否被合理矫正。两者一起讲,比单独强调某一个数字更适合训练判断能力。
CVs below X 则不是单纯给一个平均 CV,而是告诉你在不同条件下,有多少 precursors / peptides / proteins 落在 ≤10% 或 ≤20% CV 的区间中,更适合做平台级精密度判断。这其实是在强调 normalization 属于“判断实验状态”的步骤,而不是纯粹的报表加工步骤。只有先在后分析层确认 normalization 前后整体分布是否合理,后面导出的 quantities、fold changes 和候选列表才具备解释基础。换句话说,normalization 在 SpectroDive 里更像质控与解释的交界面,而不是一个隐藏在字段里的计算结果。
Differential Abundance
差异结果不应被看作“软件自动给出的最终答案”,而应被看作在质量检查之后进入的生物学解释起点。Differential Abundance 放在 Post Analysis 最后,也正是为了保持这个顺序。
因为如果矩阵质量不过关,差异分析就很容易只是把噪音变成“显著”。把它放在最后讲,能帮助新人建立更好的判断节奏。
因为一旦矩阵质量和差异结构被确认,接下来最自然的问题就是:哪些字段进入报告、哪些对象层级需要输出、哪些 QC 信息应一起保留。这就是 Reporting 课程的职责。
Candidates table 先于 Differential Abundance plots 出现,这个顺序非常关键。Candidates table 里每个 pair-wise comparison 会以颜色方向、颜色强度和圆点大小共同表示变化方向、变化比例和显著性水平;fold change 默认以平均重复的 AVG Log2 Ratio 表示;默认过滤条件是 multiple testing corrected q-value ≤ 0.05 且绝对 log2 ratio ≥ 0.58。这说明软件默认已经帮你建立了一套较保守的候选筛选门槛,但也明确允许按项目需要修改阈值。
这一节还有三个很实用的细节。第一,Candidates table 的过滤条件会自动同步到 Volcano Plot,所以学生要意识到表和图其实共用一套筛选逻辑。第二,可以通过 Column Chooser 增减列,例如把 p-value 加回来;底部的 Search 字段则适合快速定位某个蛋白或肽。第三,表格可以直接导出 Excel,Heatmap 的原始矩阵也能通过右键导出。这意味着 SpectroDive 的差异分析不是封闭黑箱,而是鼓励你在软件内筛选、在软件外复核。
Heatmap 和 Volcano 则分别承担结构化与显著性两种视角。Heatmap 会按照 Post Analysis settings 做行列聚类,更适合看条件间整体模式和聚类稳定性;Volcano Plot 把 fold change 与显著性同时放在一张图上,更适合快速定位候选。当条件超过两组时,还可以分别查看全条件分析和两两比较的 volcano,这一点在多条件设计项目里尤其重要。
Next Steps
当你已经能读懂 scoring histograms、overview、data completeness、CV 和 differential abundance,下一步可进入 Reporting 课程,把这些结果组织成 report schema、QC 历史和字段字典;如果想进一步训练图谱与字段解释,则可进入 Appendix 课程。
继续学习 report schema、QC、Appendix 8 字段解释和绝对定量交付。
继续学习附录图谱、report headers 和 glossary 训练。