基础模块定位
raw、library、FASTA、GO 与 Search Archive 共同构成 Spectronaut 的输入资源框架。只要这层关系不清,后续无论走 library-based 还是 directDIA,都会退化成机械操作。
Spectronaut 基础模块
这里覆盖 General Information、Getting Started、Structure、
Library Perspective、Pulsar、External Search Engines、
External Library Import 与 Search Archive 展开,建立 discovery DIA 的环境、
资源、library 与输入结构主线。
总述
输入资源矩阵已经把 Spectronaut 的基本世界观讲清楚了:classic DIA 需要 raw + library,directDIA 需要 raw + FASTA,而 GO annotation 则作为解释层可选输入。也就是说,Spectronaut 并不是只有一个“分析按钮”,而是根据输入资源的不同,切换不同的 discovery 路线。
raw、library、FASTA、GO 与 Search Archive 共同构成 Spectronaut 的输入资源框架。只要这层关系不清,后续无论走 library-based 还是 directDIA,都会退化成机械操作。
Spectronaut 位于 discovery 主线上游资源和下游验证、归档之间。谱库文件、数据库与版本管理与目录规范因此不只是软件设置,而是平台基础设施。
从系统准备、界面结构到 library engineering 和 Search Archive 的主线结构。
基础环境
系统要求、版本特性、安装后管理和 demo data 共同定义 Spectronaut 的运行边界。本节建立软件边界、资源规划、采集前提与首次上手流程。
| 主题 | 必须学会的判断 | 会影响后面的哪些模块 |
|---|---|---|
| 软件定位与 iRT | 理解 Spectronaut 服务 discovery DIA 大队列;iRT 不是强制,但在复杂基质和长期 QC 场景里非常关键。 | Analysis、QC、长期平台比较、复杂样本校准 |
| 20.0 更新主线 | 把 Kuiper、PTM probing、global precursor FDR、Parquet、JSON、Azure 等变化接回搜索、可信度、可视化与自动化。 | workflow 选择、后分析解释、Reporting、CLI、平台化运行 |
| 资源规划 | 按 precursor 数、run 数、临时目录和本地 SSD 规划 RAM 与磁盘,而不是只背配置表。 | 是否能稳定跑大队列、是否会中途爆内存或爆盘 |
| 方法与平台边界 | 知道哪些采集模式被支持、MS1 的额外价值在哪里、哪些方法当前不应交给 Spectronaut。 | 采集方案设计、方法验收、数据质量预期 |
| 第一次上手 | 能独立完成激活、目录规划、demo data 练习与日志路径整理。 | 首次练习、团队统一模板、后续复现 |
Spectronaut 面向 discovery DIA 大队列。单个实验可覆盖数百到数千蛋白,大型项目可支撑多条件、多重复和长周期 LC-MS runs。library、workflow、QC 与 pipeline 都建立在这一软件定位之上。
iRT 不作为 DIA 分析的强制前提,但它承担 retention time calibration 与细粒度 QC 的基础角色。引入 iRT 后,跨 run、跨批次和跨周期结果更容易保持稳定可比。
| iRT 落点 | 在 Spectronaut 中的作用 | 如果这一层不稳 |
|---|---|---|
| library / peptide reference | 把肽段 retention 坐标标准化,支撑后续 extraction 与 library transfer | 同一条 peptide 在不同来源库之间更难稳定对齐 |
| XIC RT extraction window | 决定窗口是否可以保持足够窄、足够快且足够特异 | 窗口被迫放宽,干扰增加,specificity 与速度下降 |
| QC / longitudinal tracking | 把 retention drift、峰宽和色谱稳定性正式纳入 run history | 更难判断异常是样本问题、系统问题还是方法漂移 |
| 大型队列 comparability | 让不同批次、不同梯度长度和不同 run 回到同一 retention coordinate | 跨批次比较和长期复用的风险明显升高 |
20.0 同时扩展了搜索引擎、开放修饰、识别置信度、AI、定量精度、后分析可视化和自动化接口,软件能力已经覆盖复杂 discovery 项目、长期质控与自动化运行。
这些变化可归入四条主线:Kuiper 与 PTM probing 负责打开搜索空间;global precursor FDR 与 precursor FDR per group 负责复杂数据库项目的可信度;AI、ion mobility 与新图形负责定量解释与结果呈现;Parquet、JSON、modification repository 和 Azure 负责把分析流程推向可复用的自动化体系。进入 20.0 之后,FDR 不再只是结果页里的阈值,而是和 search space、对象层级、蛋白层交付边界一起被重新定义。
| 20.0 更新主线 | 具体变化 | 核心结论 |
|---|---|---|
| 搜索引擎与开放修饰 | Kuiper 强化 unspecific directDIA;新增 PTM probing;unspecific / semi-specific directDIA 最多可提升约 85% 速度,且不受 peptide length constraint 限制。 | 20.0 把 unspecific search 与开放修饰探索正式推入主工作流。 |
| 免疫肽与复杂搜索空间 | MHC Class I immunopeptides 最多可提升约 80% 鉴定数;MHC Class II immunopeptides 和其他 unspecific searches 最多可提升约 30%。 | 这一版对免疫肽、peptidomics 和特殊数据库项目的提升非常直接。 |
| 识别置信度 | 改进 FDR 流程;新增 global precursor FDR;新增按 group 计算 precursor FDR 的 beta 特性,用于 non-canonical protein database。 | 20.0 不只追求更多鉴定,还增强了复杂搜索空间下的可信度控制。 |
| AI 与打分 | unspecific peptides 的深度学习模型关键性能指标最多可提升约 50%,并新增 novel scores。 | AI 直接进入 unspecific peptide 的识别和打分链路。 |
| 定量与可视化 | 改进 ion mobility 维度处理,提升 timsTOF 定量准确性;新增 motif、peptide length、precursor charge 图,以及 IM overview 中的 charge 叠加鉴定显示。 | 20.0 同时增强了定量精度与读图能力。 |
| 自动化与交付 | 支持 Parquet 报表导出;支持 directDIA library generation 的 JSON 设置;支持按 job 指定 modification repository;改进 SNE combine;支持从 Azure object storage 读取 raw 与 FASTA。 | 这一版明显把 Spectronaut 推向了更强的批处理、云端接入和平台化交付。 |
Kuiper 直接强化了 Pulsar 在 unspecific directDIA 上的能力,使 unspecific 与 semi-specific 搜索速度最多可提升约 85%,同时不再受 peptide length constraint 的限制。
PTM probing 则把开放修饰探索正式带入主工作流,使这套平台不仅能做标准 discovery,也能更高效地扫描潜在 PTM 信号。
MHC Class I immunopeptides 的鉴定数最多可提升约 80%,MHC Class II immunopeptides 以及其他 unspecific searches 最多可提升约 30%。
因此 20.0 并不只对常规 tryptic proteomics 有意义。对免疫肽、peptidomics 和更复杂的数据库项目,它给出的是真正能改变结果规模的提升。
20.0 改进了 FDR 流程,并新增 global precursor FDR,直接对应 peptidomics;同时加入 precursor FDR per group 的 beta 特性,对应 non-canonical protein database 场景。
这意味着 precursor 层现在被放到更核心的位置来管理可信度:先在统一 precursor 空间里做全局控制,再在复杂数据库或分组数据库里维持 group 内部的控制边界。对 peptidomics、免疫肽和 non-canonical FASTA 项目,这一层升级会直接影响最终结果到底是“命中更多”,还是“命中更多且仍然可交付”。
在更开放的 DIA 搜索空间里,claimed FDR 与实际错误比例不一定天然重合,因此 20.0 的 FDR 升级必须和 entrapment、eFDR、单 hit protein 处理和对象层级一起理解。否则只看新增鉴定数,无法判断结果质量是否同步提升。
在 unspecific peptides 场景中,20.0 的深度学习模型关键性能指标最多可提升约 50%,并增加了新的打分项。
这意味着 AI 并不是展示层装饰,而是直接改变谱图证据如何被评分、如何进入最终鉴定列表。
20.0 增强了 ion mobility 维度处理,提升 timsTOF 数据的定量准确性;同时新增 peptide motif、peptide length、precursor charge 等后分析图,并支持 IM overview 中按 charge 叠加鉴定。
因此这一版不只是“多几个图”,而是把结果解释推进到了更接近生物学模式与数据分布的层面。
Parquet 报表导出、directDIA library generation 的 JSON 设置、按 job 指定 modification repository、SNE combine 的增强,以及从 Azure object storage 直接读取 raw 与 FASTA,这几项一起定义了 20.0 的自动化层。
它们共同说明 Spectronaut 已经具备更强的批处理、模板化和平台级交付能力。
系统要求给出的不是静态配置表,而是一套与项目规模直接挂钩的资源框架。最低内存是 16 GB,但真正的大队列 discovery 环境对应的是 128 GB 或更高 RAM、2 TB 以上本地磁盘和足够高的多核 CPU。临时空间通常需要达到数据集体量的两倍左右。
更关键的是内存压力会随着 precursor 数和 run 数近似线性增加,baseline memory 还会受 vendor 与 gradient length 影响。正式环境应优先管理 Search Archive、Temporary Directory、本地高速盘和 CPU affinity,而不是把这些当成安装后的次要选项。
Linux 版本以命令行为主,支持 library generation、HTRMS conversion、directDIA、library-based DIA 与 SNE combine。仪器支持覆盖 Thermo、Bruker、SCIEX 和 Waters 主流 DIA 平台。
方法边界必须在第一课就记清:采集要求反相色谱,并尽量同时保留 MS1 与 MS2。MS1 虽然不是严格必需,但通常能贡献约 20%-30% 的鉴定提升,同时改善峰提取与打分;默认情况下它并不直接参与定量,除非在分析设置中主动启用。
支持 HRM、WiSIM-DIA、AIF、SWATH、SONAR、BoxCar DIA、FAIMS Pro、dia-PASEF、HDMSE 和经 HTRMS converter 处理的 staggered / shifted windows;不支持 multiplexed DIA 与传统 MSE。
activation key 从生成时就开始计时,并且与计算机绑定;如果网络环境受限,需要改走 registration information file 的离线激活流程。这些不是行政细节,而是第一次练习能否稳定开始的前提。
demo data 被刻意压缩到尽可能小,只服务界面和流程熟悉,不能代表真实 DIA 项目的时间、内存与存储压力。正确做法是先用 demo 熟悉流程,再回到资源与目录规划框架,重新评估正式项目。
界面结构
很多新人一开始觉得 Spectronaut 界面复杂,本质上是还没建立 Perspective、tabs、左树和右侧配置区的关系。这一段的目标,就是先把界面地图和操作习惯固定下来。
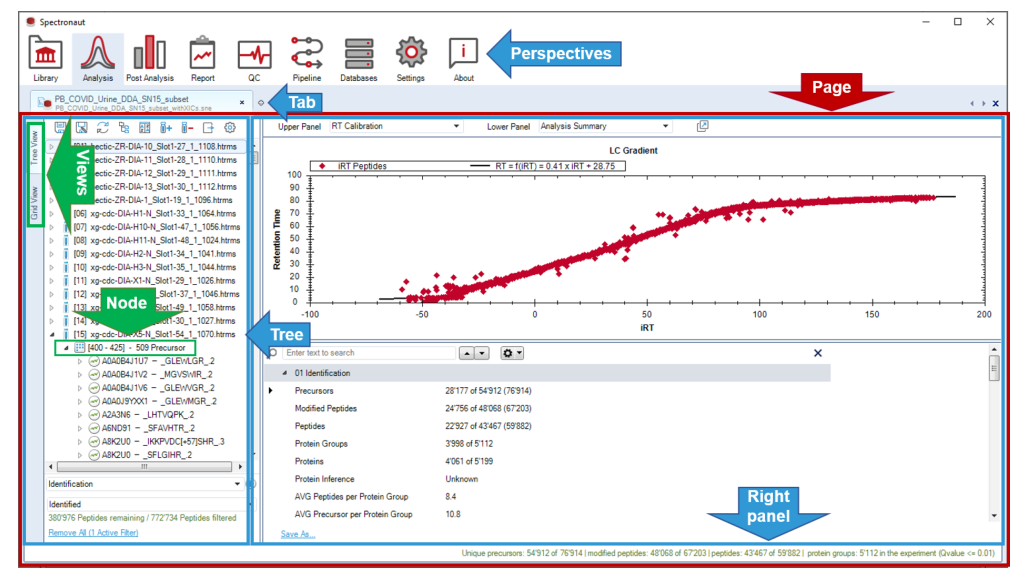
tooltips、context menus 与右键图形设置共同承载大量高价值信息。进入上机阶段后,它们直接决定 review、排错与细化效率。
raw files、library、FASTA、GO annotation、settings schema 与输出目录应在进入向导前完成确认。
谱库
Library Perspective 覆盖 Pulsar 建库、外部搜索结果建库与外部库导入。library 在这里不是孤立文件,而是连接谱库、数据库注释和搜索记录的核心层。
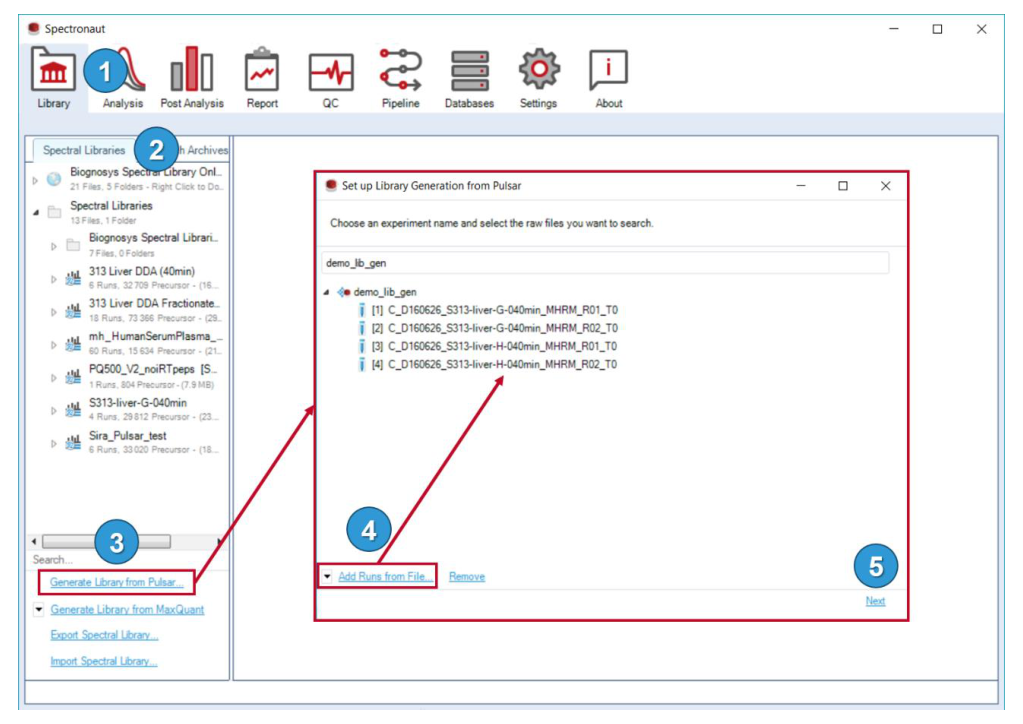
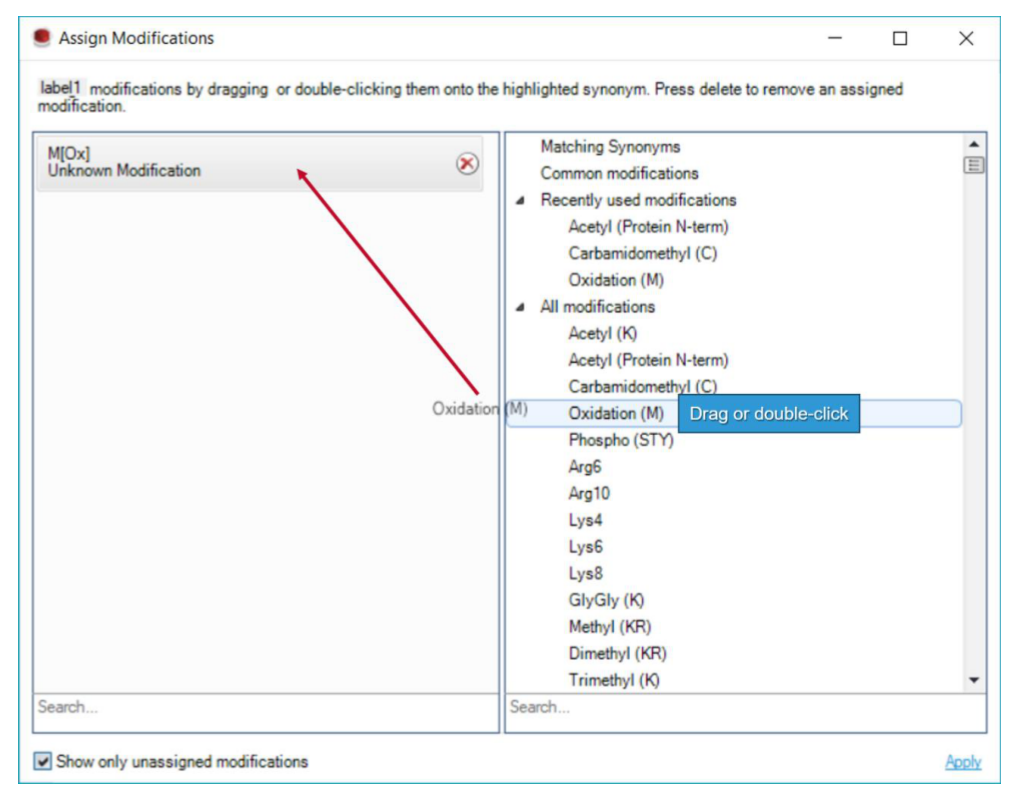
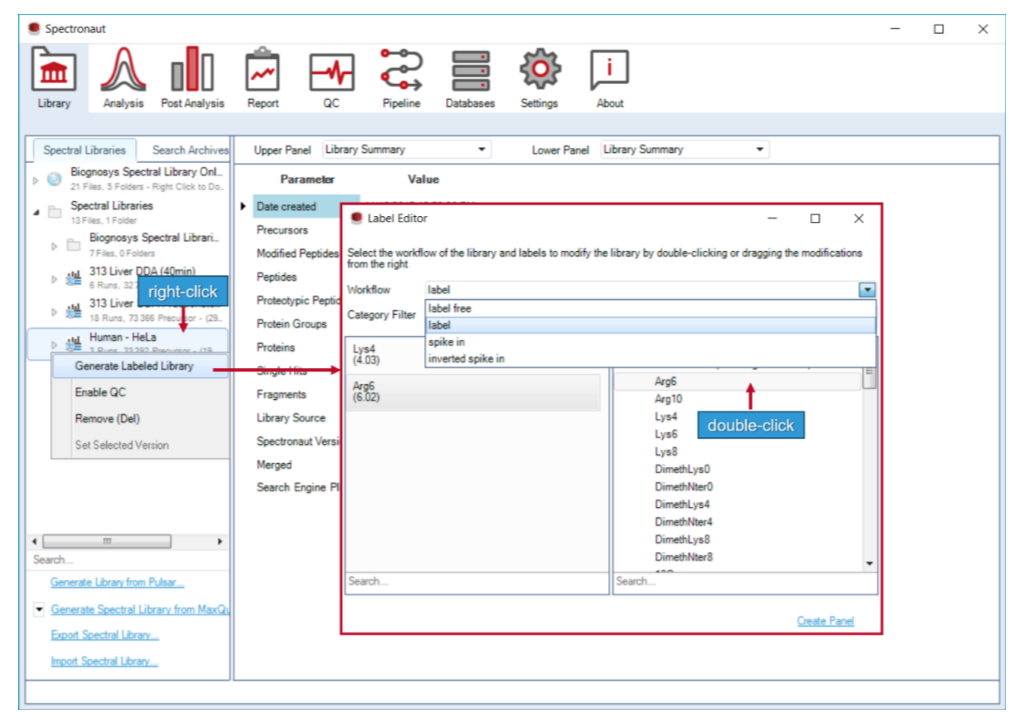
Pulsar 不是只负责“搜一下”,而是要被理解成 Search Archive 和 project-specific library 的源头。它控制 PSM、peptide 和 protein group 三层 FDR,也控制后续 library 如何被构建与复用。
关键不在于“多做 fraction 就一定更好”,而在于理解覆盖深度和 recoverability 之间的平衡。过大 library 反而可能降低分析灵敏度,这一点需要优先固定下来。
当 library 来自不同来源和不同色谱条件时,单一 iRT 中位数会损失精度。Source-specific iRT 让 Spectronaut 在深度和精度之间取得平衡,也更容易看清 hybrid library 的真正价值。
External Inputs
第 29-39 页的内容解释了 Spectronaut 如何承接历史项目和第三方搜索结果。对真实平台来说,这一点非常关键,因为大多数实验室并不总是从零开始建库。
首先要理解支持哪些 search engines,其次要理解 run mapping、modification import 和 FASTA / GO 的补充步骤。这里最关键的不是记住一个导入按钮,而是理解怎样把历史结果稳定接入当前项目。
它们说明 Spectronaut 并不是封闭只吃自家格式的工具,而是允许通过字段映射、修饰解析和表格导入承接外部生态。这对公司内部做多来源项目支持尤其重要。
搜索记录
Search Archive 不是中间文件,而是平台级搜索记录。已经搜索过的 runs 可以据此复用进新 library,而不需要每次重新搜索全部 raw。对大队列与长期项目,这一层直接决定 library 更新与历史项目复用效率。
Search Archive 直接解决历史搜索结果的安全复用问题。没有这一层,团队会不断重复搜库,也难以保持 library-wide FDR 的一致控制。
这一部分连接平台建设、方法复用和计算资源规划,同时决定 library 更新策略、项目复用策略以及搜索记录如何长期保留。
后续专题
输入资源、Pulsar、Search Archive、library columns 和系统环境理顺后,Analysis 模块承接 classic DIA、directDIA、PTM probing 和 conditions;Post Analysis 模块继续把 candidates、PCA、GO enrichment、heatmap 和 PTM analysis 串起来。
library-based DIA、directDIA、PTM probing、conditions 与 review。
candidates、PCA、GO enrichment、heatmap、volcano 与 PTM analysis。
继续查看章节索引、附录与 figure atlas。