本课定位
系统要求、Pulsar、Search Archive、外部库输入和支持的采集模式共同决定 SpectroDive 的使用边界。先把这些条件理清,后续的方法准备、分析复核和定量判断才会稳定。
SpectroDive 基础模块
这一课覆盖 SpectroDive 的入门主线,围绕
SpectroDive at a glance、General Information、Getting Started、
Structure、Library Perspective、Pulsar、
External Search Engines、External Library Import 和 Search Archives。
目标是先把靶向验证软件的输入资源、系统边界,以及谱库、外部结果和 Search Archive 的关系理清,再进入方法准备和分析模块。
Orientation
SpectroDive 并不是单纯“打开 raw file 看峰”的工具,而是一个围绕 panel、library、search archives 和 instrument method 建立起来的 targeted proteomics 平台。只有先理解这些文件关系,后面的 Prepare、Analysis 和绝对定量才不会变成机械操作。
系统要求、Pulsar、Search Archive、外部库输入和支持的采集模式共同决定 SpectroDive 的使用边界。先把这些条件理清,后续的方法准备、分析复核和定量判断才会稳定。
SpectroDive 的 Foundations 最好和 Spectronaut discovery、Auto 工作站以及标准 reference peptide kits 一起理解。这样你会更容易看懂:这里不是 discovery 起点,而是验证和方法开发的中枢。
从系统准备、界面结构到 library engineering 与 Search Archives 的主线结构。
基础模块
这一课的核心内容包括软件范围、13 版特性、Windows 系统要求、安装后管理、支持仪器和支持的 acquisition methods。这些信息共同定义了方法边界与环境准备,而不是简单导语。
这里明确强调 Kuiper 提升 unspecific spectral library generation、引入 PTM probing、改进 calibration curve plot 和 command-line activation。这说明 SpectroDive 不再只是传统 PRM/MRM 工具,而在更灵活的 panel generation 和自动化方向上也在进化。
和 Spectronaut 一样,这里明确要求把 temp 和 local search archives 放到本地大容量盘,尽量避免网络盘和虚拟机依赖。这不是 IT 细节,而是直接影响运行稳定性的条件。
| 主题 | 核心内容 | 对应判断 |
|---|---|---|
Scope |
软件同时覆盖 automated method set-up、signal processing 和 targeted data analysis | 知道 SpectroDive 不是只看峰,而是把 panel、方法导出、分析和交付串成一套系统 |
Release Features |
13 版重点是 unspecific panel generation、PTM probing、校准曲线可视化和命令行激活 | 知道这些更新分别影响 panel 设计灵活性、修饰验证、绝对定量读图和自动化部署 |
Requirements |
官方推荐 16 cores、128 GB RAM、本地高速大容量磁盘 | 能区分“demo 能跑”和“正式项目能稳定跑”是两回事 |
Post Installation |
temp、archives、results 路径最好放本地,尽量避免网络盘和 VM | 第一次部署时就会先规划目录,而不是等到报错了再迁移路径 |
Demo Data / Ready-made Panels |
它们可用于熟悉流程,但不代表真实 panel 复杂度、并发 transitions 压力和项目数据规模 | 不会把 demo 练习的速度和难度直接外推到正式验证项目 |
MRM / SRM 更像经典三重四极杆验证路线,重点是 transition 设计、dwell time 和调度密度,对应把灵敏度和稳健性放在第一位的靶向项目。PRM 强调高分辨 MS/MS 全谱和更强的选择性,对应需要后期 review 和 fragment 复核的验证任务。SureQuant 引入触发式 acquisition 思路,对应复杂基质、低丰度目标物和希望把 reference channel 真正纳入方法控制的场景。hybridDIA 和 prm-PASEF / FAIMS PRM 说明 SpectroDive 不只是传统 PRM/MRM 平台,它也能覆盖更现代的 targeted acquisition 变体,因此必须把“workflow 选择”视为正式知识点。Structure
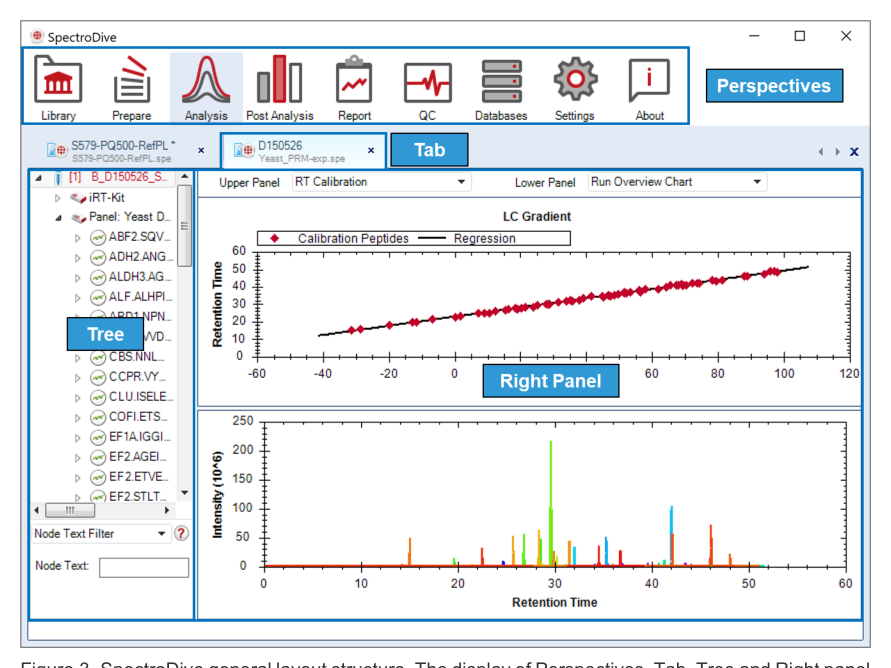
SpectroDive 的 Perspective 架构非常清楚。Prepare 管 panel 与 method,Analysis 管 review 与 refinement,Post Analysis / Report / QC 管解释和交付,Databases / Settings 则负责默认数据库、导入规则和全局设置。
因为 SpectroDive 几乎每个关键图都支持交互、右键和导出。首先要知道这些图不是静态图片,否则会错过很多复核和排错入口。
先整理出标准上手包,包括 demo data、许可证、ready-made assay panels 和 reference kits。这样无论什么时候回到这套软件,都能从同一套练习数据重新开始。
| Perspective | 主要对象 | 这层最该学会的动作 |
|---|---|---|
Prepare |
panel、RT calibration、method export | 把目标物设计成能在仪器上稳定运行的方法 |
Analysis |
raw files、peak groups、calibration curves、review tree | 判断峰是否可信、定量边界是否成立、哪些 assay 该 refine |
Post Analysis / Report |
统计图、schema、preview、export | 把 targeted 结果变成可解释、可交付的报告结构 |
QC |
run history、longitudinal metrics | 看懂长期稳定性,而不只是单次实验是否“勉强能过” |
Databases / Settings |
默认规则、import mapping、全局行为 | 把一次性操作沉淀成可复用的默认模板和统一规则 |
Library
虽然 SpectroDive 常被理解为 panel 与 PRM/MRM 软件,但 library 层同样重要。它决定 panel 的上游知识质量,也决定 later panel generation 与 targeted method 的边界。
Pulsar 在 SpectroDive 中的核心作用不只是“支持哪些 search modes”,而是它如何把 DDA、DIA、PRM with MS1 information 的搜索结果沉淀为 library 和 search archives。对 targeted 方法开发来说,这一层决定了 panel 不是凭空生成的。
Search Archives 能避免重复从 run files 重新搜索。这对平台化团队尤其重要,因为它直接关系到历史项目复用和 library 更新效率。
这部分可直接放到商业 panel、历史 library 复用和参考通道工作流里一起理解。它与真实验证项目高度贴合。
先决定是从 Pulsar 建库、外部搜索结果建库,还是直接导入 external library。这个决定会影响后面字段质量、修饰命名和 FDR 控制方式。
如果只想着“生成一个当前可用的库”,而没有把 Search Archives 作为长期文件一起管理,后续复用和扩库成本会显著上升。
真正要理解的是 library-wide FDR、modification parsing、run mapping 和字段规范,而不是只看向导是否顺利 Finish。
只有 library 层足够干净,Prepare 里生成的 panel 才会稳定。否则后面的 transition、RT 和 refinement 只是补救。
External Inputs
这部分说明 SpectroDive 并不是封闭黑箱。只要字段格式和 run mapping 处理得当,它可以稳定承接外部 search engines、历史结果和自定义 generic formats。
重点不是支持名单本身,而是 run mapping、modification import 和 library settings 的补充逻辑。只有把这些关系理顺,外部结果承接才不会变成碰运气。
它们说明 SpectroDive 允许把第三方生态的结果转成自己可管理的 谱库文件。这对多来源项目支持、合作项目承接和平台化运营都非常关键。
| 外部来源 | 对应场景 | 最常见风险点 |
|---|---|---|
| MaxQuant / Proteome Discoverer / Mascot 等搜索结果 | 已有成熟 discovery 搜索流程,想把结果迁入 targeted 平台 | run mapping、修饰命名、列名和 FDR 语义不一致 |
| BGS Generic Format | 合作方数据或内部自定义表格需要统一进 SpectroDive | 列缺失、同义列未保存、导入后对象层级不完整 |
| External Spectral Library | 复用商业 panel、历史项目库或合作单位库 | 字段兼容、修饰解析和后续 panel 细化规则不统一 |
Assign Shotgun Files…。这一步和后面的 table import / parsing rule 是连起来的,都是为了把外部生态规范成 SpectroDive 可管理对象。Search Archives
虽然 Search Archives 更常在 Spectronaut 里被提起,但 SpectroDive manual 也明确把它纳入 library generation 流程中。这意味着验证软件同样需要历史搜索结果,而不应该每次从零开始准备。
因为它直接解决了“以前已经搜过的 runs 怎么安全复用进新 library”的问题。如果不理解这一点,团队很容易反复重搜、反复重复劳动。
如果你更关注平台管理、项目复用和计算资源管理,这一部分值得反复看。它关系到 library 生命周期和搜索结果沉淀,而不只是单次分析速度。
| Search Archive 类型 | 它保存什么 | 对应能力 |
|---|---|---|
Complete Search Archive |
完整保存单个搜索的 FDR 过滤前搜索信息 | 这是最基础、最可复用的搜索结果,对应后续扩库和重新组合 |
Meta-Search Archive |
把多个 archives 再组织成更高层的组合结果 | 说明 Search Archives 不是缓存目录,而是分层管理的知识库 |
| Archives + 新 runs 组合 | 旧搜索结果与新数据一起重新控制 library-wide FDR | 正式项目里最有价值,因为它能避免每次扩库都从零开始 |
Next Steps
当系统环境、Pulsar、Search Archives、外部库输入以及谱库和搜索记录的关系已经理顺,下一步就进入 Prepare 模块处理 panel、RT calibration 和 method export;再进入 Analysis 模块处理 review、绝对定量和 refinement。
继续查看 panel generation、RT calibration、method export 和 SureQuant。
继续查看 targeted analysis、absolute quantification、review 和 refinement。
对照模块结构、附录和 figure atlas 继续查阅。