Content Audit
当前内容以约 21,857 个英文词级别的知识量级作为参照,远超普通产品页或概览页的体量。因此本页和 SpectroDive 子模块保持完整技术资料结构,而不是只保留几句功能简介。
SpectroDive 总览
本页按章节、附录、索引和 figure atlas 组织为可回查、可连续阅读的内容目录。 当前课程建设以约 21,857 个英文词级别的知识量级作为参照,目标不是摘要式介绍,而是把完整知识密度迁移进现代 HTML 学习站。
当前内容以约 21,857 个英文词级别的知识量级作为参照,远超普通产品页或概览页的体量。因此本页和 SpectroDive 子模块保持完整技术资料结构,而不是只保留几句功能简介。
本页负责总览回查,Prepare / Analysis / Reporting / Settings 负责深度课程,Textbook 负责连续教材,Workshop 负责上机训练。这样的分工更适合真正的学习和反复上手。
| 当前关注内容 | 对应起点 | 再跳到哪门深课 |
|---|---|---|
| 第一次认识软件边界 | 第 2-4 章总览、Getting Started、支持方法 | Foundations |
| 开始做 panel 与方法开发 | 第 5.2-5.3 章 Library / Prepare | Prepare |
| 开始做 review 与绝对定量 | 第 5.4 章 Analysis | Analysis |
| 需要组织结果交付 | 第 5.5-5.7 章 Post Analysis / Report / QC | Reporting |
| 要做模板化和自动化 | 第 5.8-5.9 章 Databases / Settings / Command Line | Settings |
Course Coverage
按课程顺序展开,同时补充中文解读和重点内容。
| 章节段 | 最核心的问题 | 如果读懂了,应该学会什么 |
|---|---|---|
| 第 2-4 章 | 软件边界和上手环境是否成立 | 能区分 demo 练习环境与正式验证环境 |
| 第 5.1-5.3 章 | panel 和方法是如何被设计出来的 | 能把 library、panel、calibration、method export 串成一条完整主线 |
| 第 5.4 章 | 真实数据里哪些 peaks / transitions 值得相信 | 能理解 review、grouping、refinement 的方法学意义 |
| 第 5.5-5.7 章 | 结果怎样才能被解释和交付 | 能看懂 Post Analysis、Report、QC 的分工 |
| 第 5.8-8 章 | 怎样把一次成功经验变成平台能力 | 能理解 settings、CLI、appendix 和 glossary 的长期价值 |
开头部分用于回答软件定位以及它支持哪些 targeted proteomics 工作流。
这部分是 SpectroDive 的上手准备层。除了安装和激活外,它还把 ready-made assay panels、Biognosys kits 和 PQ500 引入到技术路径里。
SpectroDive 的学习难点不在界面复杂,而在每个 Perspective 承担的角色不同。Prepare 管 panel 和 method,Analysis 管 review 和 refinement,Post Analysis / Report / QC 承担解释与交付。
这一章解释 targeted panel 的来源。panel 不是凭空列出肽段,而是基于 spectral library、搜索结果或经过明确规则的 in-silico 设计。
这部分是整条学习线里最重要的章节。它定义了 SpectroDive 的核心价值:从 panel 设计到 scheduled method export 的一整套方法开发链。
这一章讲的是“方法导出之后,怎么把真实数据变成可信结果”。如果不理解这一章,就很难真正学会 PRM / MRM 的验证逻辑。
后半段把 targeted 项目从“方法能跑”推进到“结果可解释、可交付、可持续复用”。
附录是整套内容里信息最密集的部分。真正想把 SpectroDive 纳入长期学习体系,这部分不能缺席。
Appendix Coverage
把最容易在实操中出错的附录内容集中起来,方便复训和查阅。
| 附录 | 主要解决什么问题 |
|---|---|
| Appendix 1-3 | 理解 analysis、Pulsar 和 library generation 的底层默认规则 |
| Appendix 4 | 把全局环境、目录和默认行为沉淀成团队模板 |
| Appendix 5-7 | 训练图形判读,而不是只会看一个 quantity 列 |
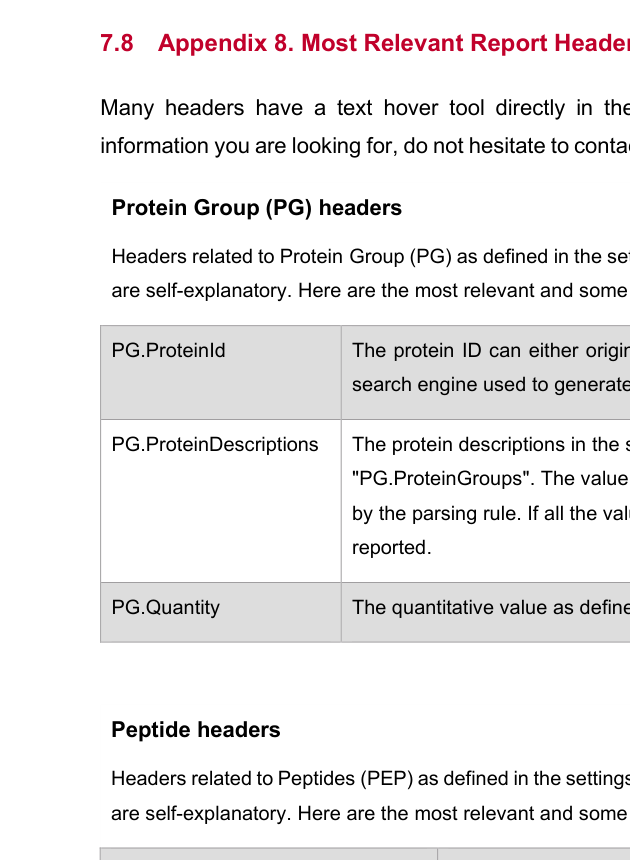
| Appendix 8 | 建立 report fields、绝对定量边界和 review 语言 |
用于解释 workflow type、condition setup、scoring、quantification、pairwise comparison 等核心参数。
适合与 Library Perspective 和 unspecific peptide / PTM probing 学习联动。
用于解释从 library 到 panel 的规则、filter、fragment 选择和 label 逻辑。
适合沉淀成团队默认设置模板,尤其是 directories、file name parsing 与 command line 行为。
适合做 plot 读图训练,尤其是 RT calibration、fragment intensity correlation、score 和 apex spectrum。
和 review、pending changes、refine assay transitions、SureQuant re-extract 密切相关。
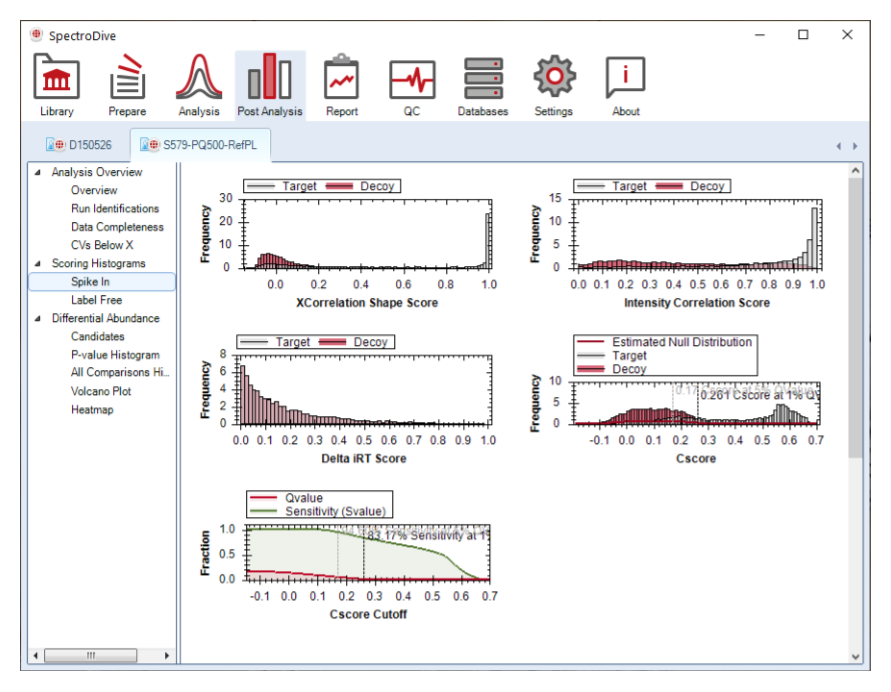
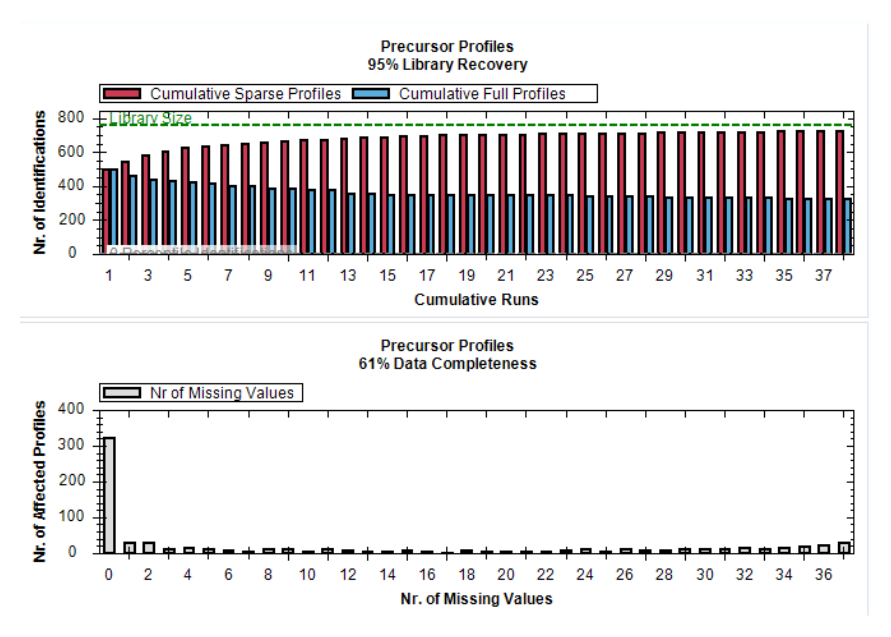
覆盖 data completeness、CVs below X、scoring histograms、volcano、heatmap 与多比较结果。
适合把输出字段和统计模板、绝对定量模板对应起来。
Figure Atlas
这些图把后分析、报表、QC、设置、方法导出和 glossary 一起接回主线结构,便于快速定位知识位置。

Advanced Modules
这里集中展开交付结构、默认环境、字段判断和术语骨架,补全 PRM / MRM 方法学的完整课程链。
| 深入模块 | 核心作用 |
|---|---|
| Report Perspective | 它决定交付语言,不只是导出按钮 |
| Settings / Global | 它决定团队默认环境,不只是个人习惯 |
| Appendix 8 | 它把“能看见字段”升级成“能读懂字段” |
| Glossary | 它是 targeted 方法学最小术语骨架 |
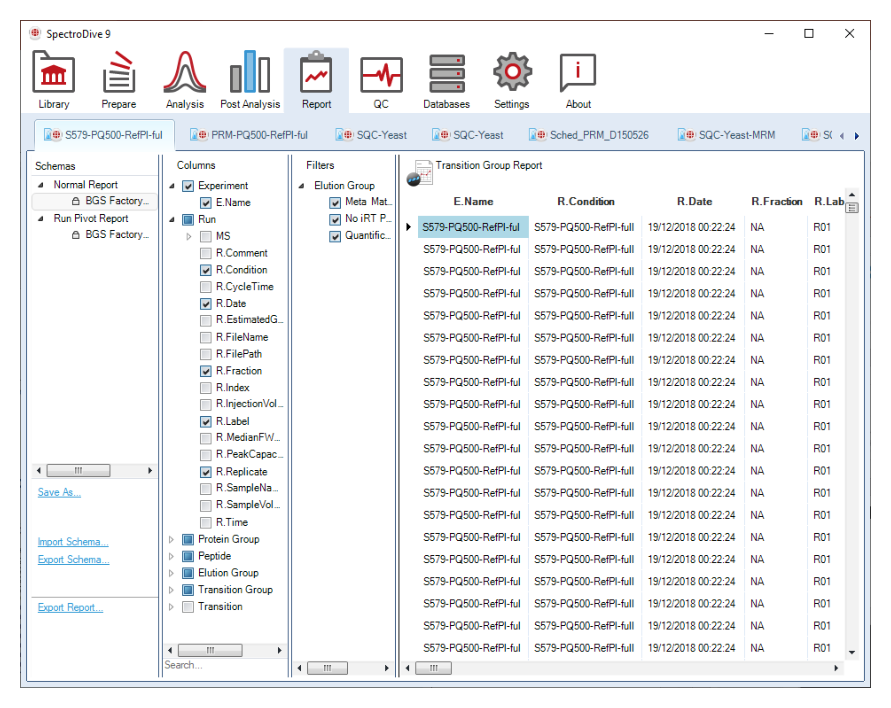
SpectroDive 的报告不是简单导表,而是一个可反复设计和保存的 reporting system。它承担验证项目交付模板引擎的角色,而不是一次性的 Excel 导出窗口。
SpectroDive 的方法开发不仅发生在 Prepare / Analysis 页面,也发生在 settings schema 和 global defaults 里。默认环境如果没有前置管理,方法开发就无法稳定复制。
_,并可自动读取 conditions annotation,这对大批量验证项目特别关键。Appendix 8 负责建立“报表读数训练”。这一模块要求同时判断 peak 质量、绝对定量边界和方法是否还需 refinement,而不是只盯着一个 quantity 列。
Glossary 不是附赠词汇表,而是 SpectroDive 入门最好的概念桥梁。它把 PRM/MRM 方法学真正需要掌握的名词压缩在两页里,特别适合转成门户词典和新人速查页。
Course Index
这里直接使用站内模块结构组织全部内容,可在当前页定位,也可进入对应课程模块继续展开。
| 课程单元 | 模块 | 在网站中的位置 | 跳转入口 |
|---|---|---|---|
| 软件定位 | At a glance / Scope / Release Features / Requirements / Supported MS / Acquisition Methods | 软件定位、平台兼容性和 workflow 边界 | |
| 入门准备 | Installing / Activation / Demo Data / Tips / Ready-made Assay Panels | 入门部署与商品化 panel 概念 | |
| Library 与界面 | Structure / Library Perspective / Pulsar / External Search / External Library / Labeled / Spike-in | panel 来源与基础信息结构 | |
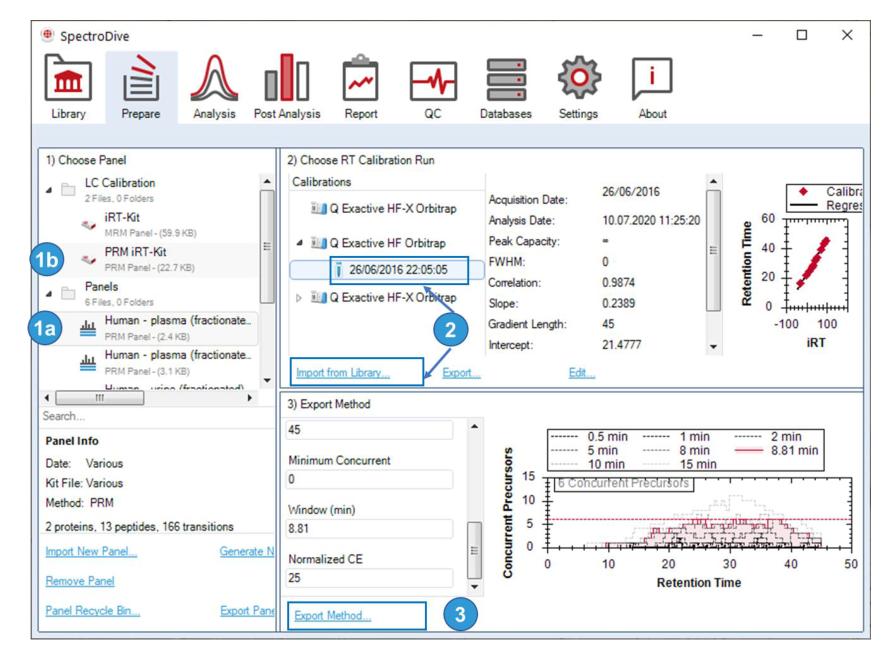
| Prepare | Prepare Perspective / Generating Panels / Importing Panels / RT Calibration / Exporting Method Files / SureQuant | 方法开发主线 | |
| Analysis | Targeted Analysis / Absolute Quantification / Review / Filtering / Grouping / Refinement / Calibration Curves Revision | 数据 review 与定量主线 | |
| 交付与 QC | Post Analysis / Report / QC | 结果解释、交付和长期 QC | |
| 配置管理 | Databases / Settings / Command Line | 配置管理和平台化运行 | |
| 附录 | Analysis Settings / Pulsar Search / Library Generation / Global Settings / Analysis Plots / Tab Options / Post Analysis Plots / Report Headers | 进阶附录和系统复习材料 | |
| 术语骨架 | Glossary | 和门户术语系统互链 |
Field Guide
这部分把高频字段、panel 骨架和定量边界集中起来,便于快速回看核心定义与判断逻辑。
| 阅读顺序 | 对应起点 | 然后再看什么 |
|---|---|---|
| panel 学习 | Q1 / Q3 / iRT / sequence / charge | 再看 response factor、ion mobility、CV 等高级列 |
| 报表学习 | schema tree 和对象层级 | 再看字段名和导出结构 |
| 绝对定量学习 | AbsoluteAmount、LLOQ / ULOQ / LOD | 再看 range-limited、CV at LLOQ、线性范围位置 |
Q1 / Q3 / iRT / RelativeFragmentIntensity / StrippedSequence / PrecursorCharge / FragmentType / FragmentNumber / FragmentCharge / ModifiedSequence / ProteinId 是 panel 学习的第一层。
`Schema tree + Column chooser + Filters + Preview` 是报表搭建主框架;`Normal Report` 偏长表分析,`Run Pivot Report` 偏透视展示。
PeptideResponseFactor、PeptideAbsoluteAmountUnit、ProteinScalingFactor、ProteinAbsoluteAmountUnit,以及 `EG.AbsoluteAmount / LLOQ / ULOQ / LOD` 直接关系到绝对定量可落地性。
LLOQ、ULOQ、dilution factor、workflow type、reference channel 一起构成 calibration curves 的核心判断框架。
Appendix 8 需要与验证报告模板、LIMS 字段和绝对定量汇总表做映射,尤其是 `PEP.IsProteotypic`、`EG.AbsoluteAmountRangeLimitted`、`EG.Cscore` 和 `TG.CompensationVoltage`。
Course Links
如果已经定位到某一章需要继续深挖,可直接跳到对应子模块或技术总述,不必一直停留在索引式页面里。
聚焦系统要求、界面结构、Pulsar、外部库输入和 Search Archives。
聚焦 panel、RT calibration、method export 和 SureQuant。
聚焦 targeted analysis、absolute quantification、review 和 refinement。
聚焦 scoring histograms、data completeness、CV、normalization 和 differential abundance。
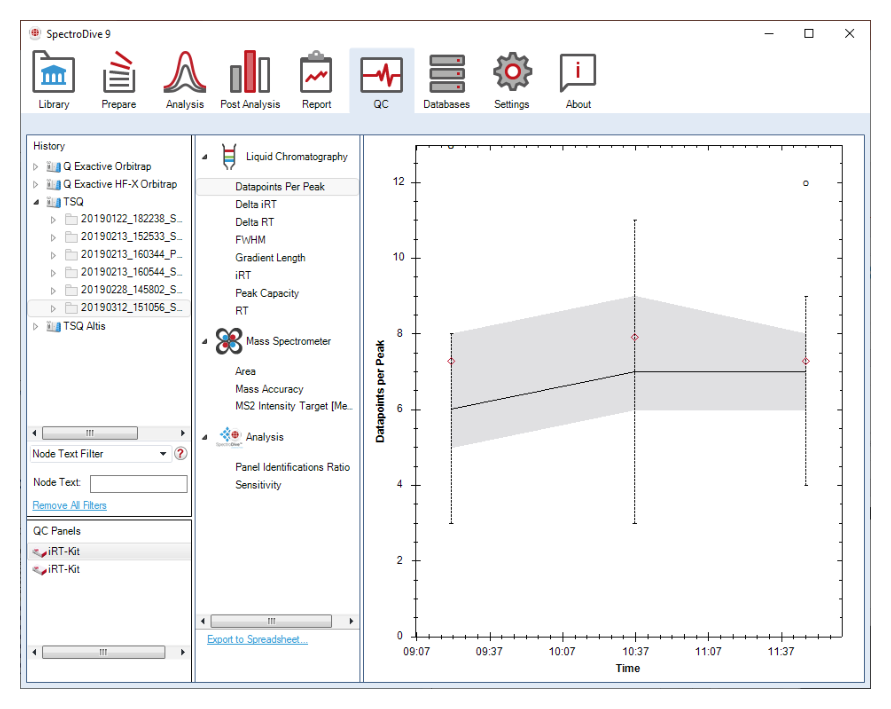
聚焦 Post Analysis、report schema、QC history 和 Appendix 8。
聚焦 databases、settings schema、command line 和 glossary。
聚焦附录 1-8、plot 判读、report headers 和 glossary 速查。
分别适合连续阅读和任务化上机训练。