软件定位
SpectroDive 的核心在于把 assay panel、iRT calibration、scheduled acquisition、绝对定量和质量控制串成标准化工作流。
panel 设计、RT 校准、调度窗口和 calibration curve 处于同一条逻辑链上。
SpectroDive
SpectroDive 覆盖靶向验证与方法开发的基础环境、Library、Prepare、Analysis、绝对定量、Reporting、QC、Settings、Glossary 与实操训练。
全站检索
检索结果会按章节生成节选,并可直接跳转到对应内容。
总述
它服务于自动化 acquisition method set-up、ion signal processing 和 targeted proteomics data analysis。panel、方法导出、信号提取、绝对定量和长期 QC 属于同一套平台逻辑。
SpectroDive 的核心在于把 assay panel、iRT calibration、scheduled acquisition、绝对定量和质量控制串成标准化工作流。
panel 设计、RT 校准、调度窗口和 calibration curve 处于同一条逻辑链上。
SpectroDive 服务 PRM / MRM 为主的 targeted proteomics,同时覆盖 SureQuant、hybridDIA、prm-PASEF 与 FAIMS-PRM。方法导出、信号处理、可视化、定制报表与自动 QC 共同构成它的核心范围。
Temporary Directory 与 Search Archives 应固定在本地高速盘,并尽量避免网络盘和虚拟机依赖。大量本地 I/O 与稳定的第三方库调用都建立在这一前提之上。
章节结构
本部分按 SpectroDive 的工作流组织:基础环境与 panel 思维建立边界,Prepare、Analysis、Reporting、Settings 与实操训练构成完整靶向验证链路。
软件定位、系统环境、支持的仪器与 acquisition modes 共同定义 targeted 平台的边界。
围绕 Pulsar 建库、外部搜索结果导入、外部光谱库导入和 spike-in / labeled library 组织上游知识输入。
library / FASTA / sequence list 生成 panel 后,RT calibration、method export 与 SureQuant 继续定义方法开发链路。
围绕 targeted analysis、absolute quantification、review、tree filtering、grouping、panel refinement 和 iRT refinement 展开。
把 scoring histograms、differential abundance、report schema 和 QC panels 连成一条结果解释与交付主线。
schema、命令行、标准化批处理和 glossary 构成平台化运行层。
| 模块 | 核心内容 | 核心内容 | 进入模块 |
|---|---|---|---|
| 基础环境 | 软件定位、平台兼容性、工作流边界、安装和演示环境准备 | 先理解 targeted 平台的能力边界与运行条件 | |
| Library | Library、Pulsar、外部结果导入、光谱库和 panel 的上游知识来源 | 建立 panel 来源、数据库注释和搜索记录的整体理解 | |
| Prepare | panel 生成、导入、split、修改、RT calibration、method export 与 SureQuant | 建立方法开发与调度导出的完整思路 | |
| Analysis | targeted analysis、absolute quantification、review、grouping、refinement 与 calibration 曲线修订 | 把方法真正落到数据 review 与定量决策上 | |
| 结果解释与交付 | Post Analysis、Report Schema、QC、字段阅读与结果输出 | 把靶向验证结果转成可解释、可交付、可追踪的结构 | |
| 设置与自动化 | Databases、Settings、Command Line、Glossary 与附录训练 | 平台化运行、批处理和术语体系 |
SpectroDive 的内容跨度覆盖环境准备、panel、analysis、QC、command line 与 glossary。软件页对应整体结构,方法开发、结果解释、交付与管理分别拆入各子页面。
操作说明、字段说明与术语说明在这些模块中保持同一条知识链。
Content Audit
当前页面覆盖基础环境、panel、analysis、absolute quantification、report、QC、settings、glossary 与上机训练的完整路径。
这里同时覆盖方法开发主线、report schema、QC、settings、command line 与 glossary。
软件页对应全局结构,Foundations 对应系统准备与 谱库文件,Prepare / Analysis / Post Analysis / Reporting / Settings 展开细节,Textbook 与 Workshop 对应连续阅读与上机训练,章节目录承担回查与附录索引。
页面结构同时容纳连续阅读、上机准备、字段回查与模块切换,软件页负责主线分区与模块入口。
Subcourses
当前页面拆分为基础环境、方法开发、数据解析、结果解释、交付层、设置与标准化、连续阅读、任务化实操和章节目录九类入口。
系统要求、界面结构、Pulsar、外部库导入和 Search Archives。
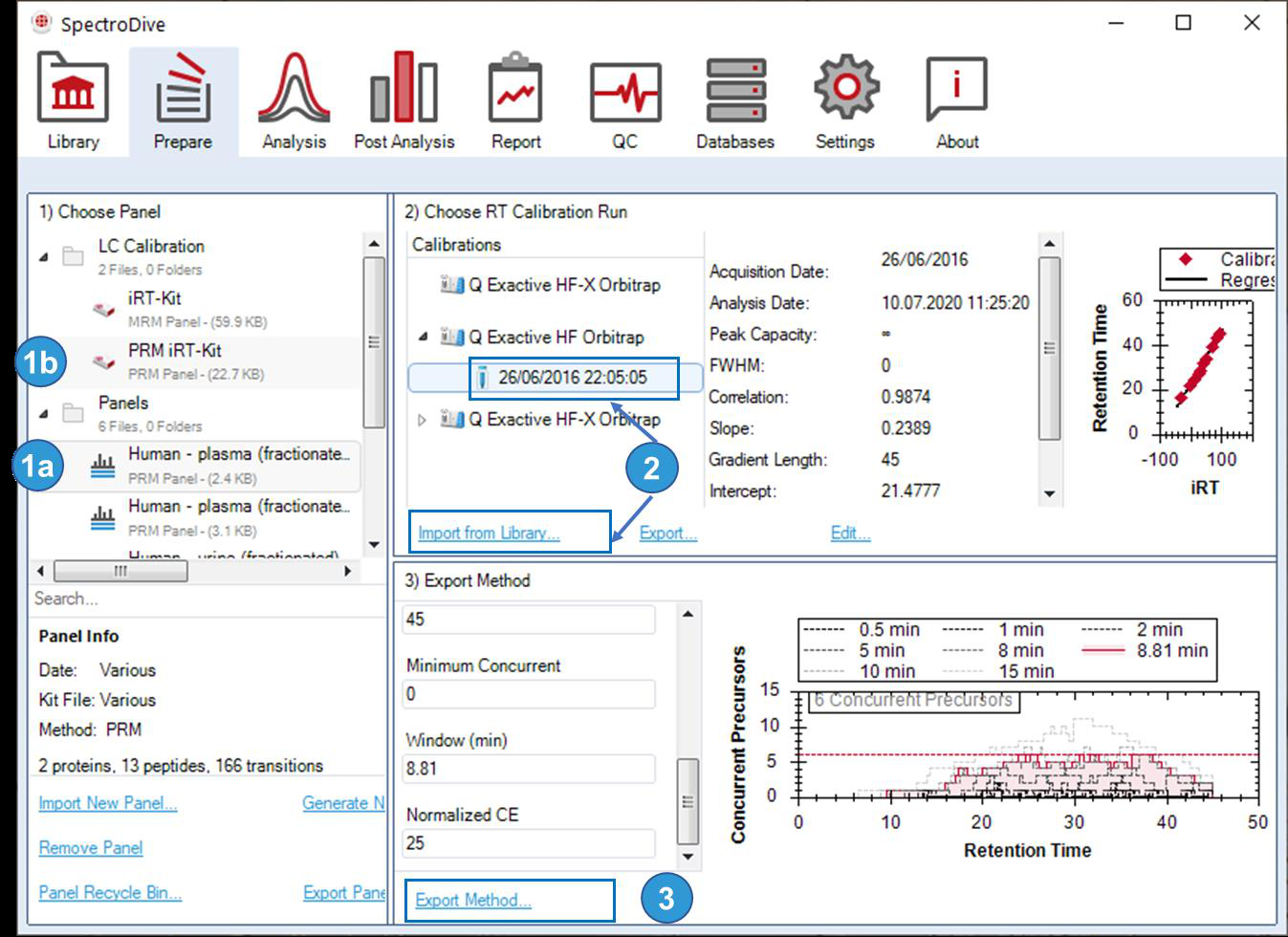
panel 生成、导入、split、RT calibration、method export 和 SureQuant。
targeted analysis、condition annotation、absolute quantification、review 与 refinement。
analysis overview、scoring histograms、data completeness、CV、normalization 和 differential abundance。
Post Analysis、report schema、QC history 和 Appendix 8 字段解释。
databases、settings schema、global defaults、command line 和 glossary。
把附录 1-8、plot 读图、report headers 和 glossary 单独做成训练页。
以连续技术文本方式展开主要模块。
按任务化上机路径覆盖环境准备、report、QC 和 command line。
继续查看章节索引、附录、figure atlas 与细化模块。
Foundations 负责输入数据与界面结构,Prepare 负责 panel 与方法导出,Analysis 负责真实 run 解析与 refinement,Post Analysis 负责矩阵质量与差异解释,Reporting 负责交付结构,Settings 负责模板与自动化接口,Textbook 负责连续阅读,Workshop 负责任务化上机,章节目录 负责章节与附录回查。
这样设计后,用户既可以按章节顺序浏览,也能按问题回到对应页面,而不会在一张长页里来回找锚点。
Targeted Workflow
Prepare 与 Analysis 主线共同定义 panel、调度、校准曲线、免疫富集延伸与 refinement 的关系。
| 工作流 | 关键词 | 软件关键节点 | 典型应用 |
|---|---|---|---|
| PRM | 高分辨率靶向、fragment review、panel optimization | Prepare、Targeted Analysis、Fragment Refinement | biomarker 验证、机制 readout |
| MRM | transition 数控制、scheduled windows、dwell time | Panel Split、Export Method、RT Calibration | 大 panel 验证、常规检测 |
| SureQuant | triggered acquisition、reference channel、自动触发 | Prepare、SureQuant 设置、raw re-extract | 低丰度验证、复杂基质 |
| SISCAPA-PRM | SIS、anti-peptide antibodies、immuno-enrichment、complex matrices | Prepare、Analysis、Calibration Curves、Reporting | 超低丰度 biomarker、CSF / plasma readout、药效与转化验证 |
| Absolute Quantification | calibration curves、LLOQ、ULOQ、dilution factor | Calibration Curve Node、Condition Setup、.ccs | 临床转化、剂量-反应、绝对丰度 |
从 library / FASTA / sequence list 到 panel、RT calibration、method export、analysis 和 refinement 的工作链。
PRM 更强调 fragment-level review 与 refinement,MRM 更强调 transition 数控制、dwell time 与 panel splitting,SureQuant 引入 reference-triggered acquisition 与 re-extract 逻辑,SISCAPA 则把抗体富集加入前处理层,把复杂基质和超低丰度目标推进到可定量区间。absolute quantification 进一步把 workflow type、reference channel、LLOQ / ULOQ 与 .ccs 管理拉进来。
Platform Stack
验证端平台的核心不是单独一台仪器,而是四极杆隔离、Orbitrap 高分辨碎片读出、可选的 FAIMS 背景抑制,以及 SpectroDive 对 panel、calibration curves 和 report schema 的承接。Q Exactive 建立了 HRAM PRM 的基线,Exploris / Exploris 480 则把高通量、稳定 FAIMS 接口和 routine absolute quantification 推进到更常规化的验证平台形态。


| 验证端平台形态 | 对应工作流 | SpectroDive 中最关键的模块 | 典型项目 |
|---|---|---|---|
| Q Exactive / Exploris HRAM PRM | 常规 PRM、panel 验证、机制 readout、routine biomarker verification | Prepare 的 panel / RT calibration,Analysis 的 review,Reporting 的字段字典 | 候选 biomarker 验证、药效 readout、组织与体液 targeted follow-up |
| Exploris 480 + FAIMS-PRM | 复杂基质、低丰度靶标、更严格的 background suppression | Prepare 的调度导出,Analysis 的 absolute quantification,Reporting 的 LLOQ / ULOQ 边界 | CSF / plasma 低 pg/mL readout、复杂基质靶向定量、转化验证 |
| SISCAPA + Orbitrap HRAM targeted | SIS、抗肽抗体富集、LC-PRM / FAIMS-PRM、校准曲线 | Prepare 的 panel 结构,Analysis 的 calibration curves,Reporting 的可报告范围 | 超低丰度 biomarker、膜蛋白、药物开发与临床转化验证 |
第一,HRAM PRM 的价值不只是分辨率更高,而是完整碎片离子证据与 panel review 能同时保留,这一点直接决定 SpectroDive 的 refinement 和报表字段解释能力。第二,Exploris 与 FAIMS-PRM 的组合主要服务低丰度和复杂基质场景,它解决的是 background suppression 与可量化区间,而不是简单增加一个硬件部件。第三,SISCAPA 把灵敏度提升前移到样本处理层,但定量是否真正成立,仍然要回到 Orbitrap HRAM targeted、calibration curves、workflow type 和 LLOQ / ULOQ 的共同判断。
Panel Schema
第 29-30 页给出了导入 panel 所需的关键列,这部分是很多新手第一次做 targeted panel 时最容易出错的地方。
| 字段 | 中文解释 | 关键点 |
|---|---|---|
| Q1 / Q3 | 前体与碎片离子的理论 m/z,不应四舍五入 | 它们不是随便填的表格字段,而是整个 panel 能否被正确调度和解析的基础 |
| iRT | 反相色谱保留时间映射到 iRT 空间的值 | 如果 iRT 不准,调度窗口、峰提取和结果灵敏度都会受影响 |
| RelativeFragmentIntensity | 相对碎片强度 | 有助于提高检测限和 fragment ranking |
| ModifiedSequence / ProteinId | 修饰序列与蛋白归属 | 决定修饰位点、标记策略和后续过滤能力 |
| PeptideResponseFactor / ProteinScalingFactor | 绝对定量所需的响应因子 | 如果要做浓度估计而不是相对变化,这些字段必须提前规划 |
Q1 / Q3 错误会导致采集或提取对象偏移;iRT 错误会先表现为 scheduling 不准,再表现为分析速度和 sensitivity 下降;RelativeFragmentIntensity 缺失或不合理,会影响 fragment ranking 与 detection limit;ModifiedSequence / ProteinId 不清楚,会影响修饰解析、过滤和报告;绝对定量字段未提前设计,后续补入往往已经来不及。
Hands-on
以下步骤把 Prepare 与 Analysis 两大部分手册内容压缩成了可执行的训练顺序。
panel 可从 spectral library、FASTA 或 sequence list 开始生成。
当 panel 太大时,需要执行 split panel,并结合并发 transitions 图控制窗口与并发数,避免信噪比恶化。
线性、非线性、DIA-based calibration 和 library-based calibration 都需要区分,尤其要判断什么时候可以直接从 library 导入 RT calibration。
窗口宽度与并发数共同决定调度质量,MRM 场景尤其需要避免 dwell time 过低。
如果目标是绝对定量,必须提前定义 calibrant runs、dilution factor、workflow type、LLOQ / ULOQ 计算方式和 .ccs 复用策略。
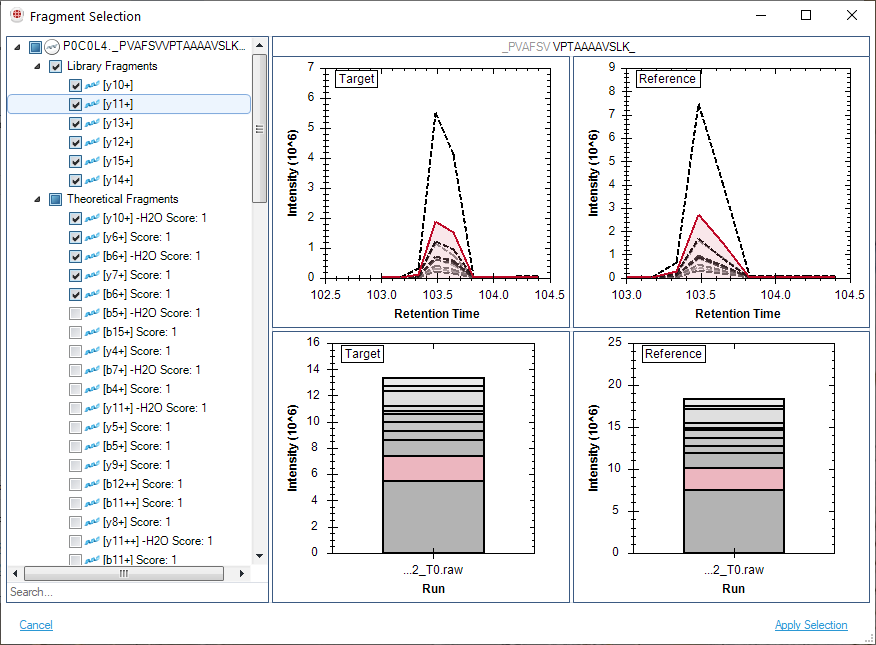
新手往往只会看峰,不会把筛选后的 transitions 和 refined iRT 真正提交到 panel 中,这一步必须专门训练。
这条路径先定义 panel,再处理 calibration 与 method export,之后进入 analysis setup 与 review,最后进入绝对定量、report 和 refinement。
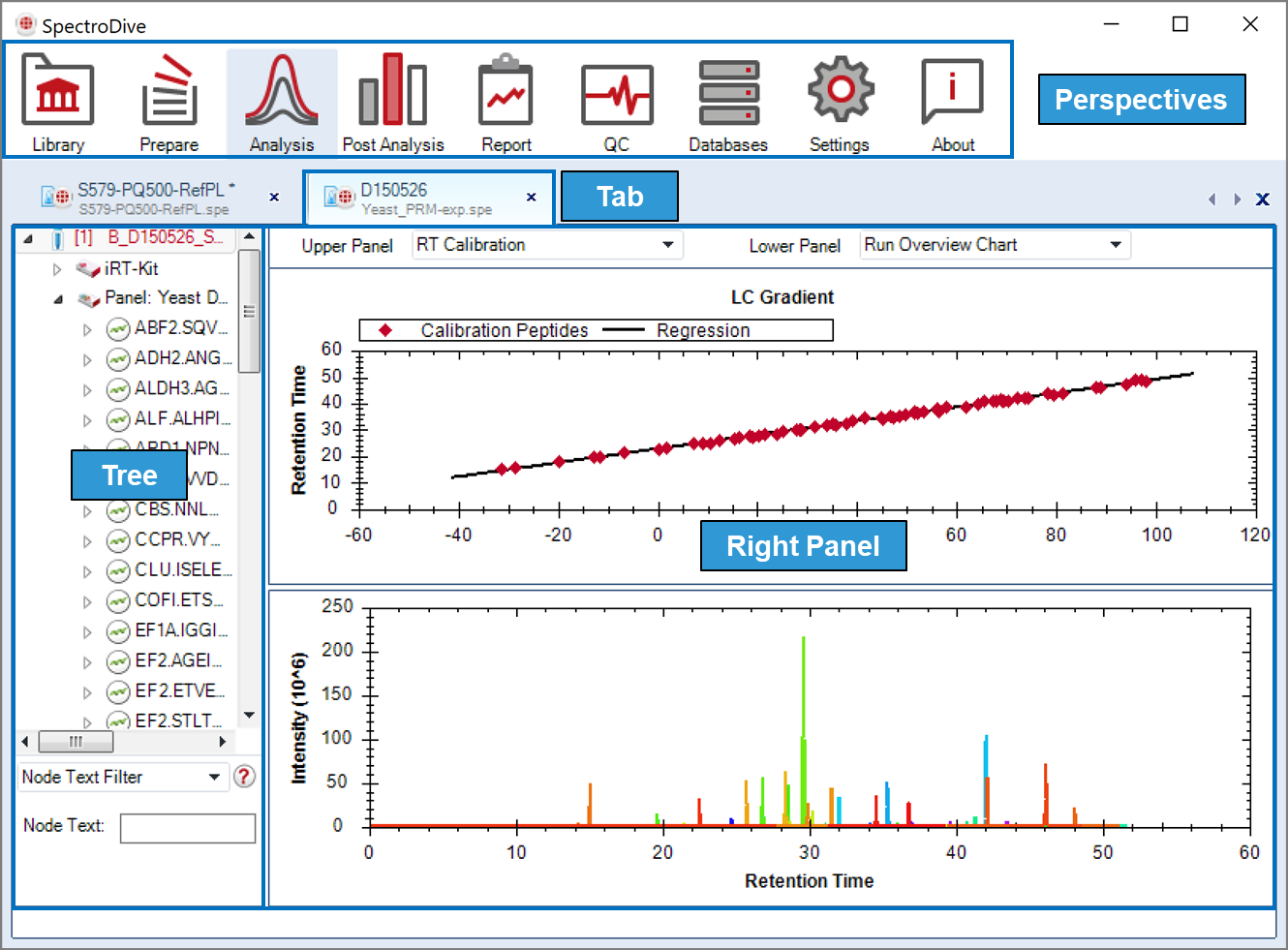
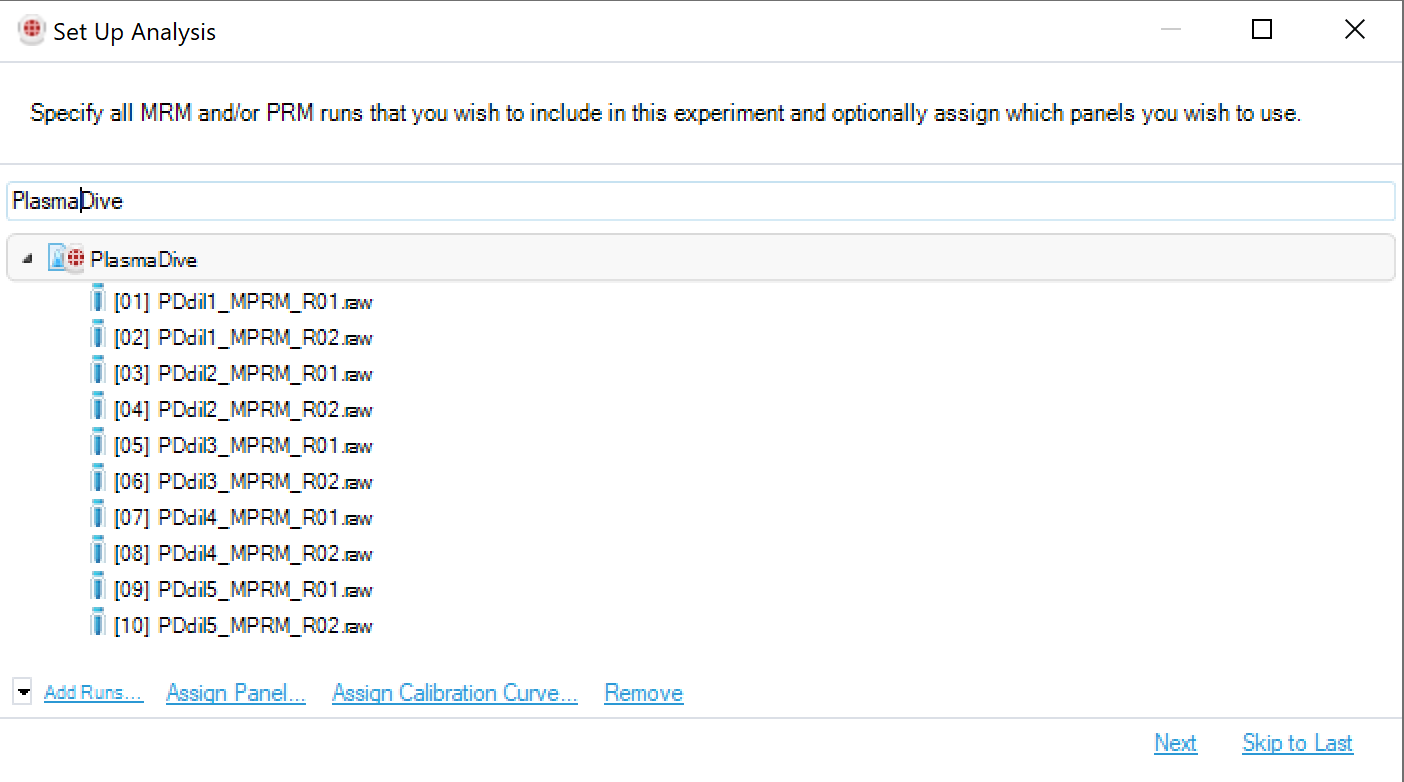
Interface Atlas
SpectroDive 图谱按照 targeted workflow 展开,覆盖基础界面、谱库、Prepare、Analysis、绝对定量、Reporting、QC 与附录图表。
References
理论文献、软件模块和方法专题共同支撑 PRM / MRM、SureQuant、SISCAPA 与绝对定量的完整学习路径。
Foundations、Prepare、Analysis、Post Analysis、Reporting、Settings、Textbook、Workshop 分别对应环境、方法开发、结果复核、报表、设置和实操训练。
Foundations / Prepare / Analysis / Post Analysis / Reporting / Settings / Textbook / Workshop
集中覆盖 Prepare、Analysis、appendices、global settings、plots 与 glossary。
对应高分辨率 targeted proteomics 的理论起点,以及 PRM 在验证与精准定量中的位置。
集中覆盖 panel、SureQuant、PQ500 等官方路线描述。
覆盖抗肽抗体免疫富集、SIS、复杂基质中的低丰度读数,以及 SpectroDive 如何承接 calibration curves 与报告链。
对应 discovery 到验证整条链条在当前临床转化蛋白组学框架中的位置。